










“喂,你好,我是你的声音克隆体,今天我就是你的嘴替。”
想象一下,如果你的声音能够如此自由地“分身有术”,生活会不会变得更加有趣?
大家好,我是 Henry,不,我是 Henry 的克隆体。今天,我要带大家认识一位新朋友——GPT-SoVITS。这位朋友可不简单,它能完全模仿你的声音,并替你说话,除了中文和英文,它甚至还可以说你完全不会的日文!
它学习特别快,只需要一点点你的声音样本,就能变得和你一模一样。
今天,我就带大家认识这位AI界的新朋友,看看它能做什么,最重要的是,我们如何能使用它,来打造一个专属自己的声音克隆体。不管是在朋友面前炫技,还是在朋友圈展示你的AI技能,或者只是单纯想做一个自己的克隆体,GPT-SoVITS都能帮你实现!
所以,系好安全带,我们即将启程,探索声音克隆的奇妙世界!
你身边的 AI 声音
最近 AI 大火,各种 AI 应用层出不穷,大家的关注度大多集中在 ChatGPT 这样的对话式 AI,或 Stable Diffusion 这样图像生成式 AI,你是否注意到,AI 声音其实也在悄然崛起。
如果大家常刷短视频,或许能发现一个奇怪的事情:诶?怎么现在博主的声音都一样?诶?怎么每个电影开头,都是“这个男人叫小帅,这个女人叫小美”,声音还都一样?
不用惊讶,其实这就是用 AI 制作的声音。
不同于 ChatGPT 的经常封号,MJ 的付费订阅,以及 Stable Diffusion 的显卡要求,制作 AI 声音就显得特别容易,现在网络上的 AI 声音工具琳琅满目,层出不穷。我们普通人最容易接触到的大概就是剪映了,剪映为我们提供了非常多的声音模型,我们可以非常方便的使用剪映进行文本转语音。这其中不少音色,我们在抖音短视频都能经常刷到

当然了,除了剪映,现在有很多工具都能实现语音转文本,输入一段文字,它们就能为你输出一段指定音色的语音。
不过很显然,我们今天要聊的重点并不是这个,而是要让AI克隆你自己的声音,用你的声音去读出一段话!
声音克隆魔法师
市面上能克隆声音的软件其实不少,但是 GPT-SoVITS 的优势在于,开源免费、本地部署,配置要求不高。
GPT-SoVITS,这个名字听起来就像是魔法师的咒语,但它其实是一套开源的声音克隆工具。它利用了当下最火的 AI 技术——GPT(Generative Pre-trained Transformer)模型,加上 SoVITS(Speech-to-Video Voice Transformation System)技术。它就像一位魔术师,能够把你的声音完整克隆下来。
GPT-SoVITS 的作者是国内大佬,B 站账号“花儿不哭”,也曾是 RVC 变声器的创始人,以下是作者的原教程,更加详细:
【耗时两个月自主研发的低成本 AI 音色克隆软件,免费送给大家!【GPT-SoVITS】】 https://www.bilibili.com/video/BV12g4y1m7Uw/?share_source=copy_web&vd_source=b8d0b2c4c1a84965a2546f0efe2f5759
以及作者提供的官方 GPT-SoVITS 教程:https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e
GPT-SoVITS 最大的优势在于,它完全开源免费,并且基于本地部署,最过分的是,它对电脑配置要求还不高!(相比于 Stable Diffusion 好很多,不过仍然要求 4G 显存的 N 卡)
-
模仿,它是认真的
想象一下,作为一名最多只会说英语,并且可能说的还不是很流利的中国人,你顶天也就只会中文和蹩脚英文,然而,GPT-SoVITS,你能轻松的实现中文、英文、日文的无缝切换,并且按照现在的趋势,未来支持更多语言也是迟早的事情,到时候,别说精通三门语言了,精通三十门语言都不在话下 -
快速上手,无需等待
而且,GPT-SoVITS 最酷的地方在于,它不需要你的声音“大数据”。只需要一点点样本,它就能快速学习并模仿你的声音。这就像是拥有了一本快速成才的秘籍,即便是 AI 界的新手,也能迅速上手,成为声音克隆的高手。 -
个性化你的声音
每个人的声线都是独一无二的,GPT-SoVITS 能够捕捉到这些细微的差别,并将其转化为数字信号,从而生成一个专属于你的声音模型。这意味着,你可以用它来创建一个声音分身,无论是在视频里,还是在虚拟世界中,都能以你的声音出现。
你的声音很好听,现在是我的了
各位观众老爷,准备好克隆自己的声音了吗?放心,我们只需要两样东西就可以启程:一段你的声音和一点耐心。
准备工作:首先,我们需要一段你的声音样本。这就像是为 AI 提供一张你的声音照片,好让它能够模仿你。你可以随意说一段话,比如:“今天的月亮真圆啊!”或者“请帮我克隆我的声音!”,录下来,不管是一段还是多段素材,加起来一共大概一分钟左右时长即可,这就是我们声音克隆的起点。
接下来,你需要的只是一点耐心。因为,虽然 GPT-SoVITS 非常聪明,学习速度很快,但它毕竟不是一秒钟就能学会所有东西的魔法师。给它一点时间,它就能给你一个惊喜。
搭建环境
现在,让我们来搭建环境。
看官们大可放心,GPT-SoVITS 的环境搭建非常容易,我会带你一步步搭建好 GPT-SoVITS 的必要环境
- 下载源代码
GPT-SoVITS 是在 github 的开源仓库(https://github.com/RVC-Boss/GPT-SoVITS),熟悉github的同学自行下载即可,不管是用git clone,还是直接 download zip 都行
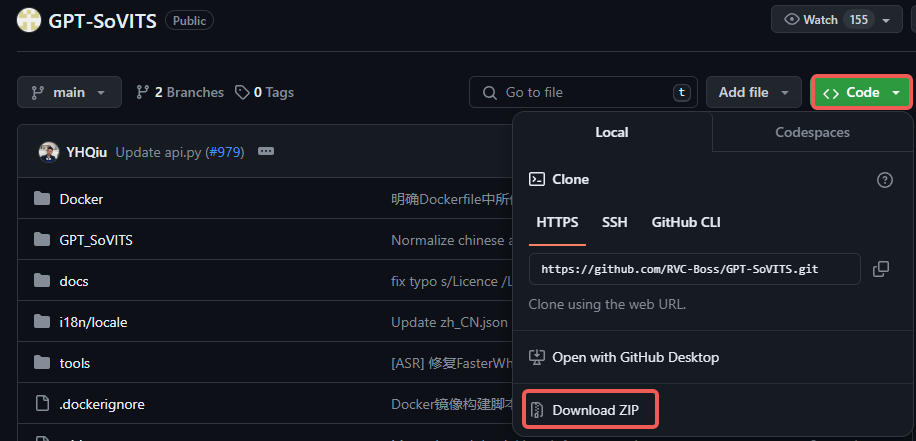
不懂的朋友也没关系,这里我直接贴上仓库代码的下载地址(https://github.com/RVC-Boss/GPT-SoVITS/archive/refs/heads/main.zip),下载好解压到本地任意目录即可
- 安装 Python
GPT-SoVITS 基于 Python 开发,所以 Python 环境肯定是必要的,我们下载 3.9 版本即可。
这里我推荐 3.9.13 版本(https://www.python.org/downloads/release/python-3913/)
为了让 python 环境隔离,我们用命令行进入到 GPT-SoVITS 的根目录下,然后输入以下命令创建虚拟环境
python -m venv runtime
用记事本打开 go-webui.bat,并编辑其中的 python 为正确路径
runtime\Scripts\python.exe webui.py pause
- 安装依赖包
依赖包就像是 GPT-SoVITS 使用的各种插件,插件齐全,它才能运行起来,否则缺胳膊少腿的,运行过程中会看到各种糟心的报错。
我们先安装必要的依赖包,用命令行进到刚刚创建的虚拟环境目录下 runtime\Scripts,然后分别执行以下几条 pip 命令安装
pip install install ffmpeg cmake
pip install pytorch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 pytorch-cuda=11.8
pip install -r requirements.txt
- 下载 ffmpeg
FFmpeg 就像是 GPT-SoVITS 的 DJ,负责处理音频。它可以帮助你把声音文件变得适合 GPT-SoVITS 学习。
我们需要下载好 ffmpeg 和 ffprobe 放到 GPT-SoVITS 的根目录下,下载地址(https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-full.7z)

我知道各位都很忙,可能没有耐心一步步安装,没关系,我为大家准备好了整合包下载地址,解压即用!后台回复“声音克隆整合包”获取!
声音克隆
环境准备好了,我相信你已经迫不及待了,现在我们就来看看要如何使用 GPT-SoVITS 来克隆声音
这是基于 python 的开源项目,所以其实有多种使用方式,可以直接用 python 调用接口,或使用作者提供的 webui 或 gui 界面,这里我们就讲大家最容易接受的 webui 使用方式
打开根目录下的go-webui.bat,即可启动GPT-SoVITS webui!
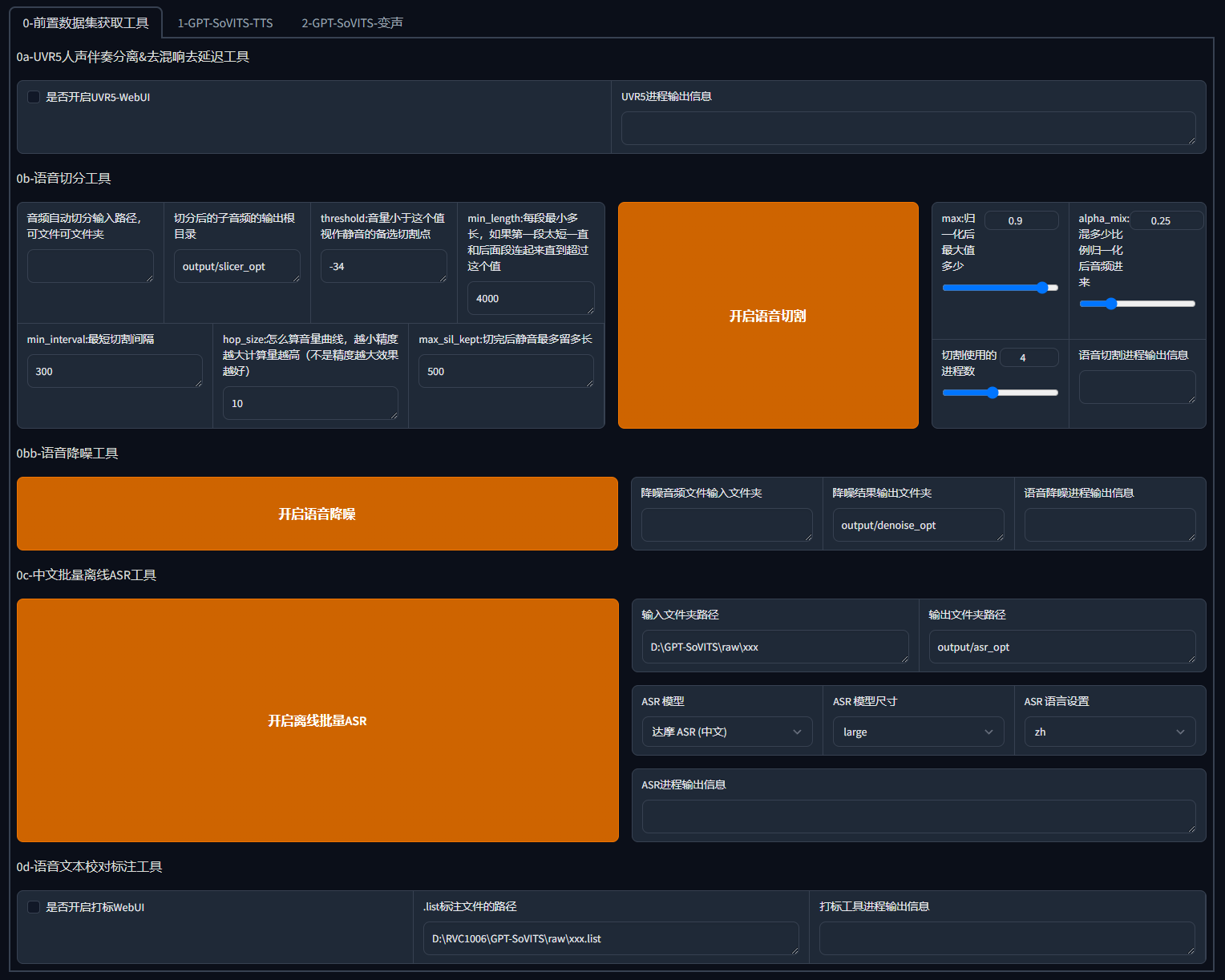
别被界面吓到了,其实它一点都不复杂,仔细看,作者为了让我们快速上手,甚至已经做好了步骤的标注,大的页签分为了 0 和 1(2 暂时还未开放),而在大页签下,也标注了 0a,0b,0c,0d,1Aabc 等这些一眼就能看出执行顺序。
如果你还是不明白,没关系,我带大家一步一步克隆声音!
1.人声伴奏分离
为了得到更好的素材,我们需要得到干净的人声,通过 UVR5 工具,分离人声和伴奏(没错,市面上那些需要收费分离人声和伴奏的工具,这里本地免费使用)
点击 0a 中的"是否开启 UVR5-WebUI",稍等一会,webui 会启动一个新的页面
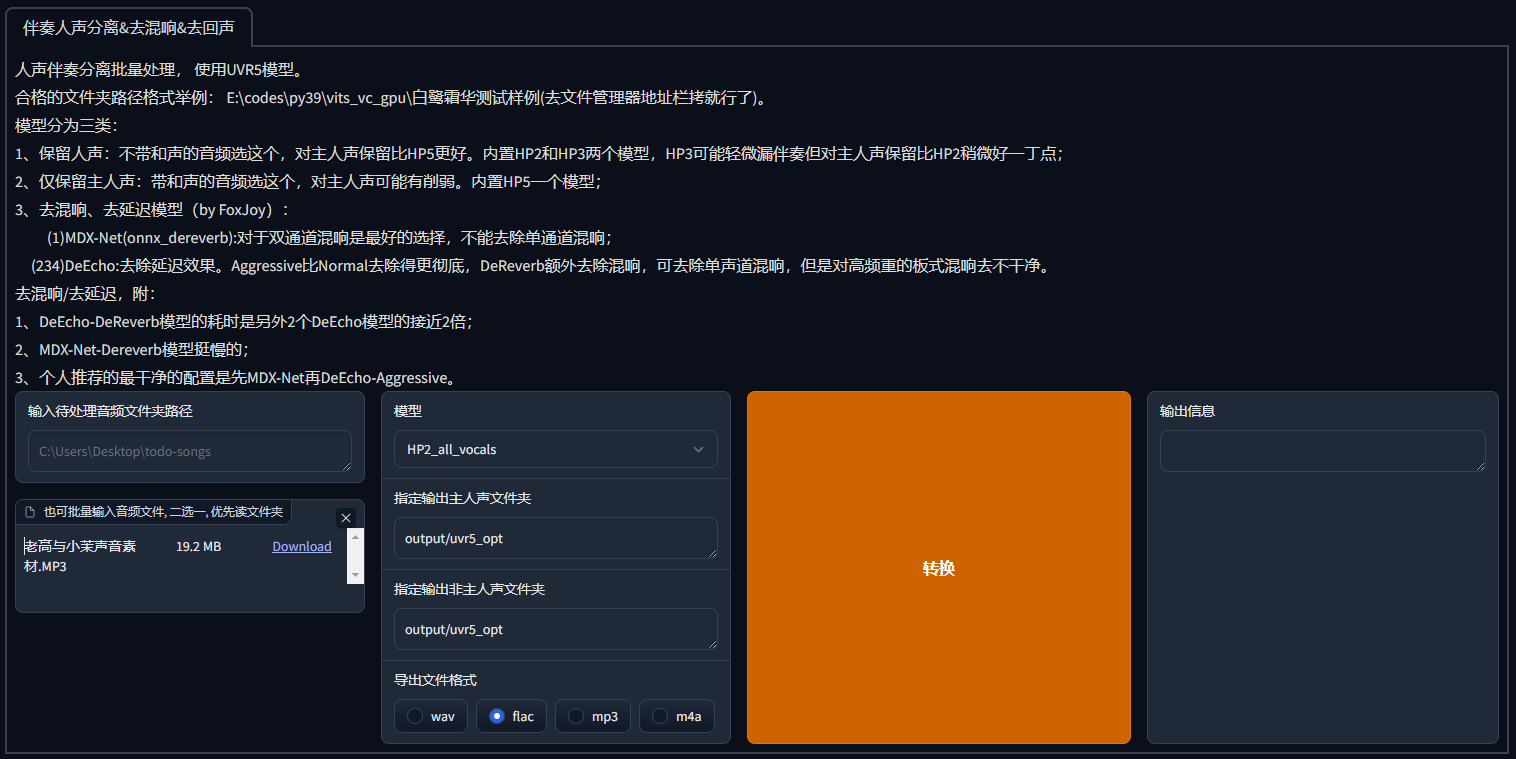
- 选择素材可以直接输入目录,或者用拖拽,或直接上传的方式,来上传音频原素材
- 选择转换模型时,在界面上方,作者也给出了建议,仅供参考。我常用的模型是 HP2,当然这不是绝对的,你可以亲自尝试哪种效果更好
- 输出文件夹可以采用默认路径,在根目录下的 output/uvr5_opt 中
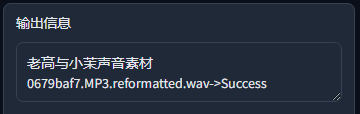
一切准备就绪后,点击转换,看到输出"Success",即可得到人声(vocal)和伴奏声(instrument)分离的文件了
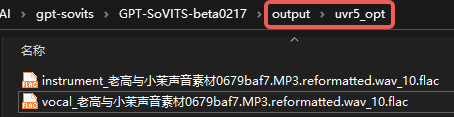
由于我们是用于声音克隆训练,所以instrument伴奏文件用不到,这里可以直接删掉
用完之后,直接关闭这个页面,并且在原先的页面中关闭"是否开启 UVR5-WebUI"的勾选,这样可以释放一部分的显存
2.语音切分
接下来,我们需要对原素材进行切分,分成多个小文件来方便处理。我们把上一步得到的人声伴奏分离后的文件目录输入即可,其他参数保持默认即可,等我们玩熟练了,再去微调其他参数。
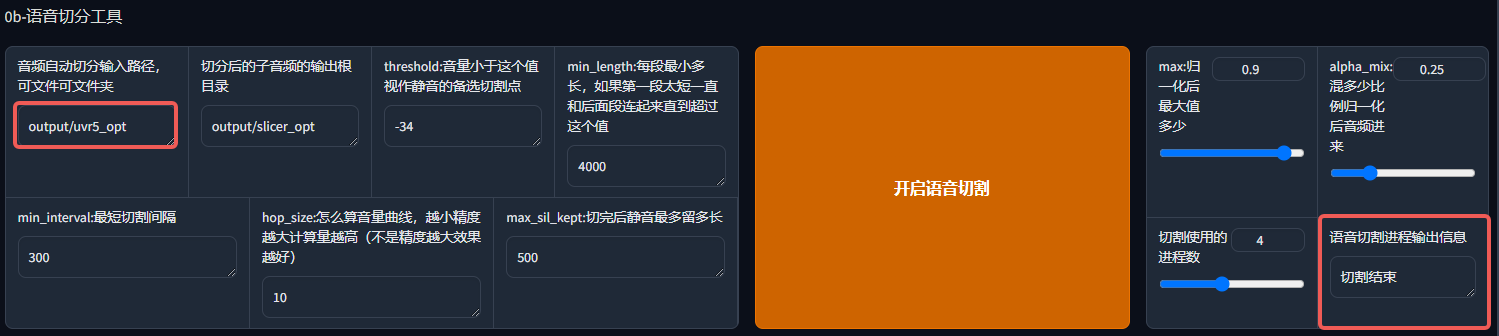
同样的,看到输出"切割结束",我们就能在对应目录下看到输出的切割好的文件了
3.语音降噪
我们继续顺着作者的标注往下走,是语音降噪,这个功能显而易见可以对语音的再一次提纯,我们把上一步输出的目录输入即可,输出目录仍然保持默认。

看到"语音降噪完成",我们就可以看到降噪后的文件了
4.批量离线 ASR
这一步简单来说,就是自动打标,对你提供的声音素材进行语音转文本,对每一句话打上标签,让 AI 知道你每一句说的什么。这一步同样的,我们吧上一步输出的目录输入,输出目录保持默认。
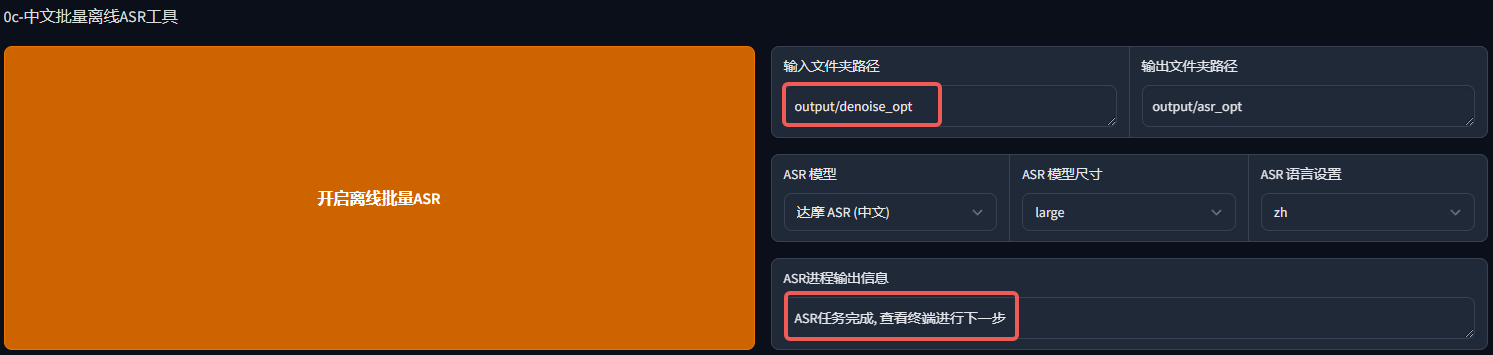
输出"ASR 任务完成",我们就能对应目录下看到一个生成的 denoise_opt.list 文件,这就是 AI 自动打标得到的结果集

5.语音文本校对
上一步由 AI 对我们的素材进行了自动打标,但是 AI 难免会听错,所以我们需要这一步来进行手动打标校对,输入上一步自动打标得到 list 文件的路径,再开启打标工具

打开之后就看到这样的界面
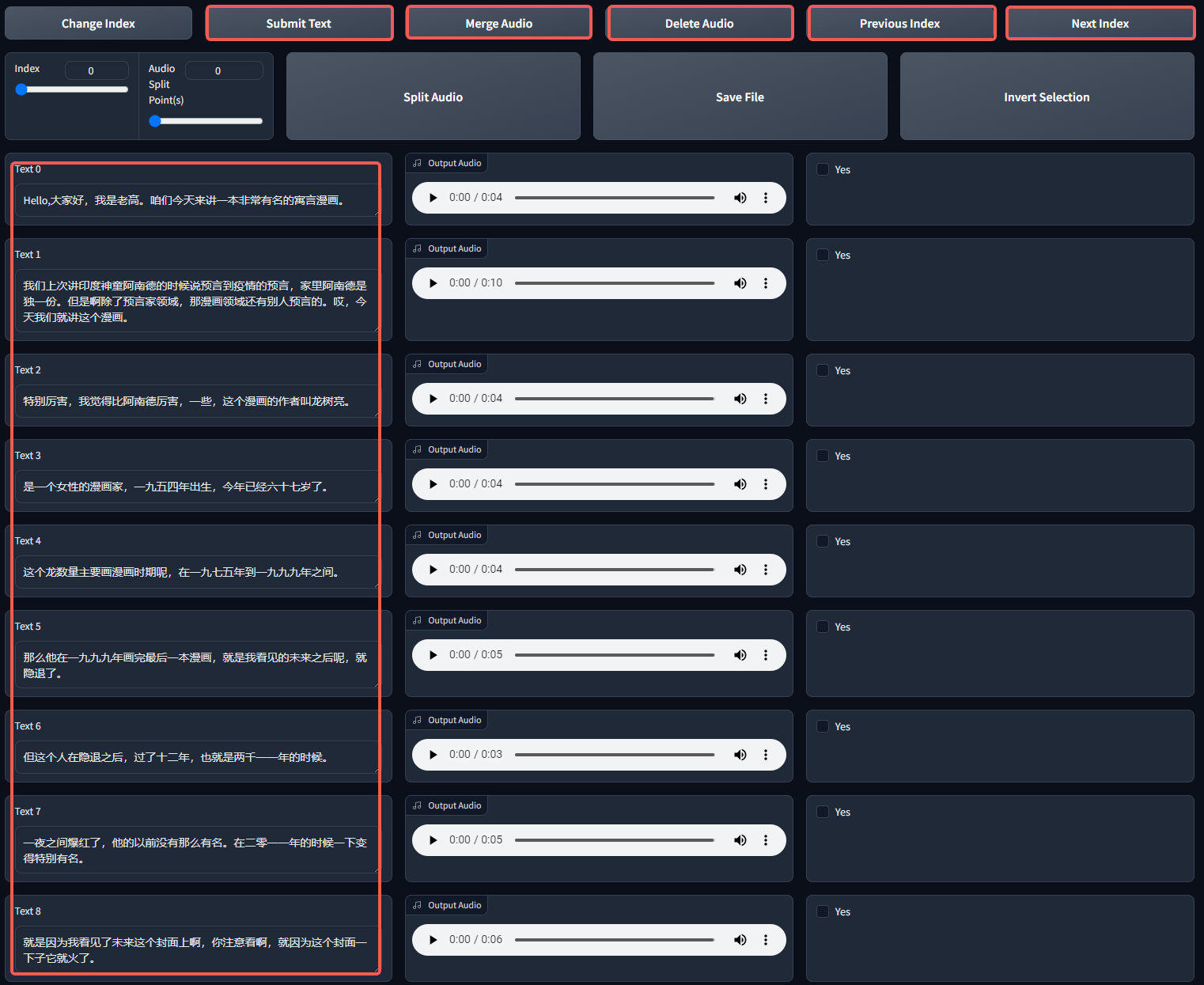
这其中我们主要用到以下几个地方:
- Text:听一遍所有的语音,并核对打标文本是否正确(包括文字和停顿,若该停顿的地方没有停顿,我们需要手动打上逗号),修改错误的部分
- Merge Audio:合并语音片段,若感觉语音片段过短(比如一句话就一两个单词),可以将多段勾选 Yes 框的语音合并
- Delete Audio:删除语音片段,若感觉语音片段有问题(比如原声处理不干净),可以将多段勾选 Yes 框的语音删除
- Previous Index 和 Next Index:翻页,因为片段可能很多,所以存在多页数据
- Submit Text:提交文本,需要注意的是,以上的任意一条改动在翻页之前以及最后关闭前,都点击一下 Submit,它就相当于 Word 的 Ctrl+S,只有你编辑了半天最后发现白做了,才知道有多痛苦(别问我怎么知道的!)
编辑完成之后,其实我们所有的修改都已经保存到了上述提到的 denoise_opt.list 文件中。同 uvr5 一样,用完关闭这个页面,并在原页面取消勾选"是否开启打标 WebUI",这一步就完成了。
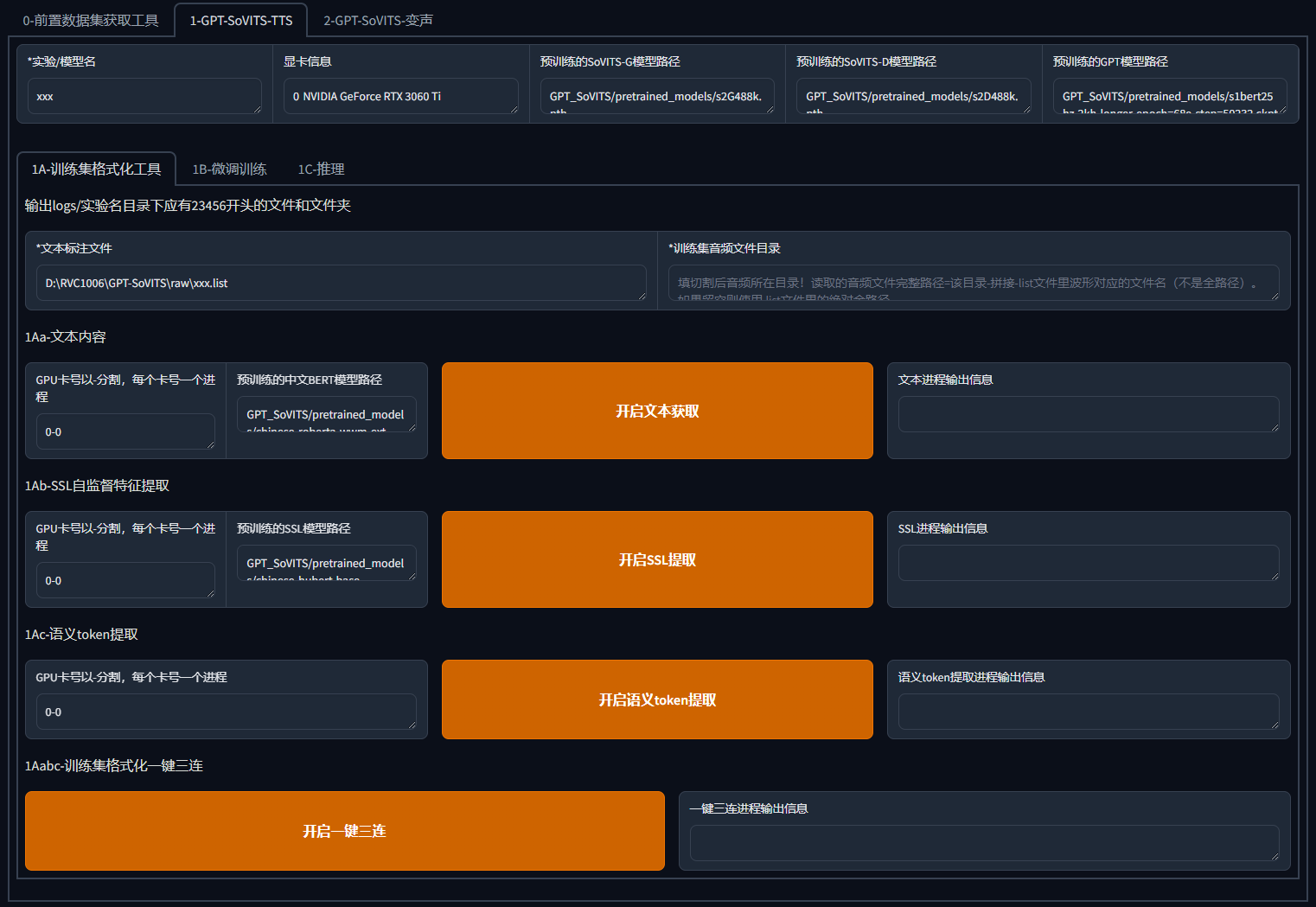
6.训练集格式化
别着急,这是训练前的最后一步了,磨刀不误砍柴工!
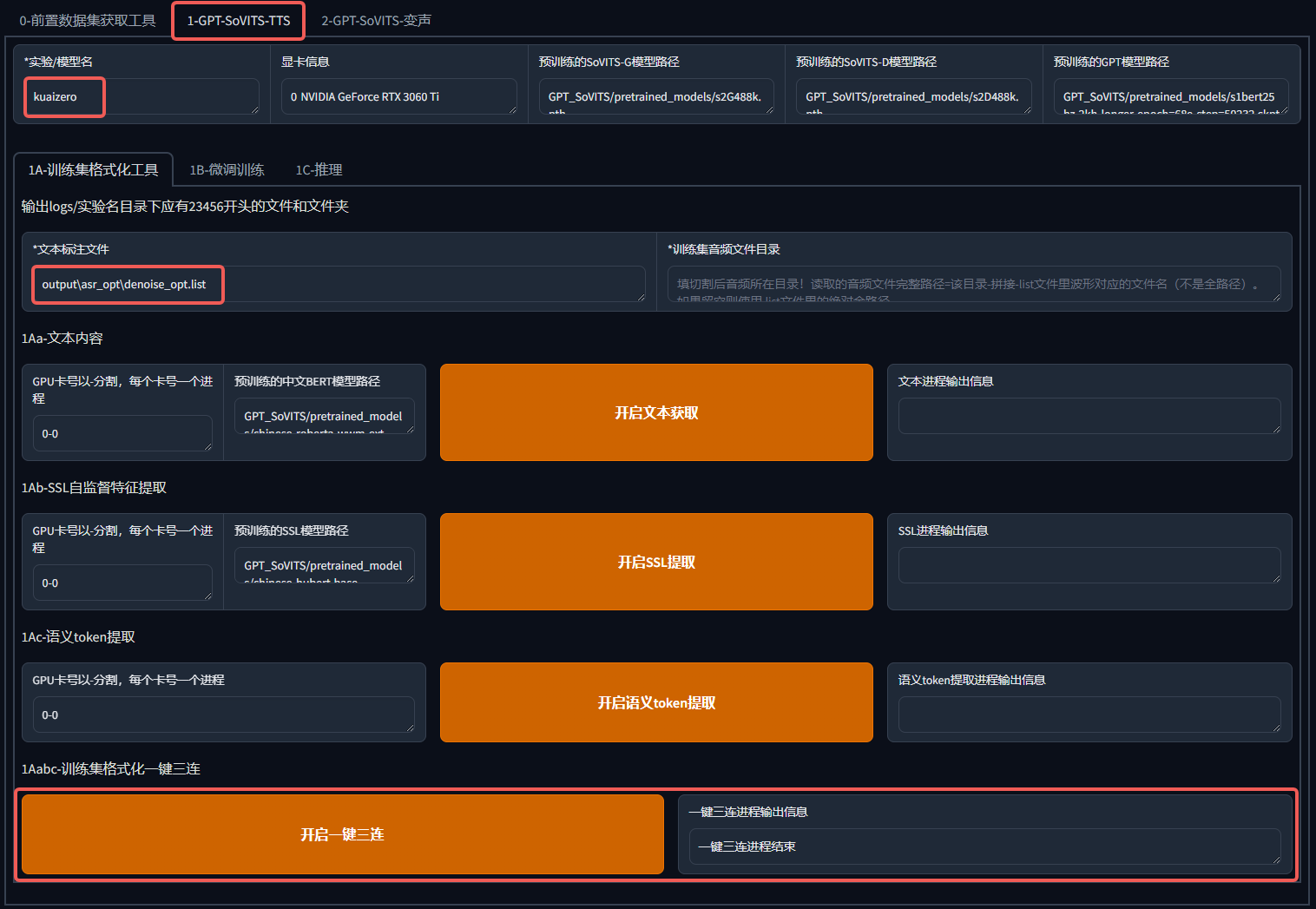
我们对要克隆的声音模型取一个名字,把上面得到的 denoise_opt.list 填写到标注文件中,然后点击"开启一键三连",即可开始进行格式化,看到"一键三连进程结束",这一步就完成啦
7.微调训练
好了,到了万众瞩目的最关键的一步了,就是训练模型!
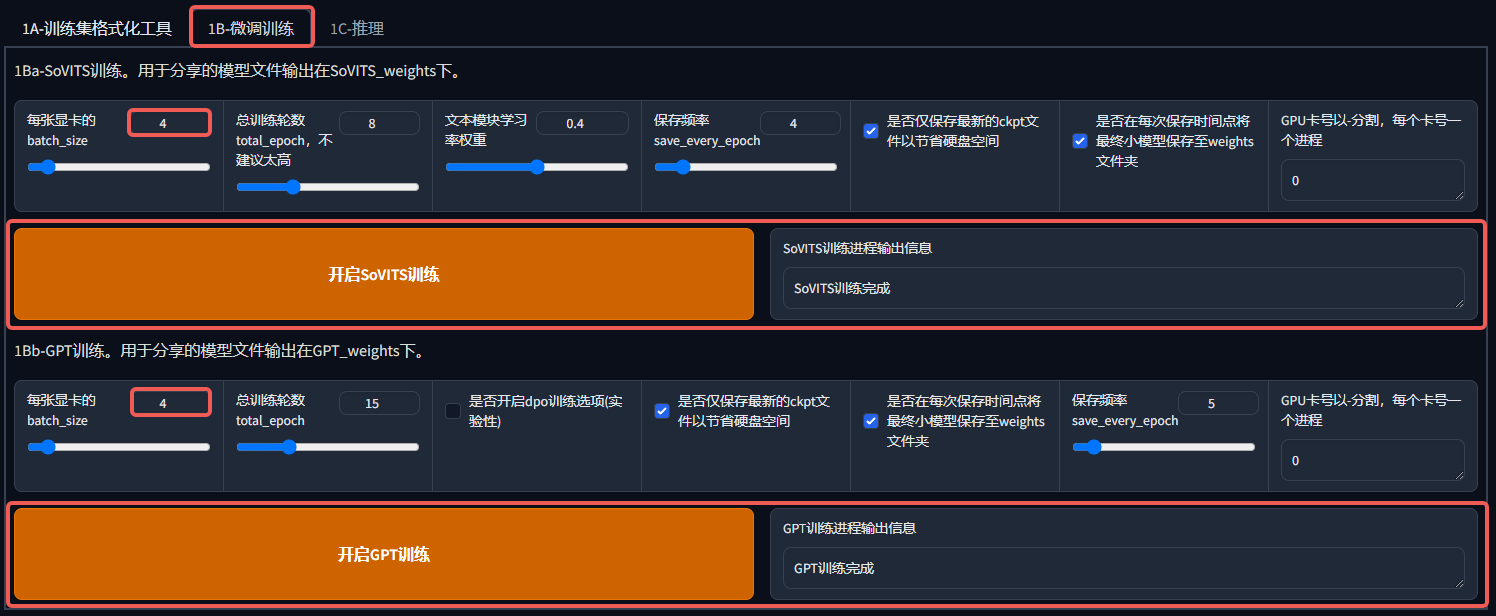
训练分两步,训练一个 SoVITS 模型和一个 GPT 模型,其中大部分参数保持默认,可以修改显卡的 batch_size,也就是并行训练队列,数字越大训练速度越快,同时对显卡消耗也更高,显卡好就多开点,显卡不好就少开点。
训练结束,我们就能分别得到 GPT 模型(GPT_weights 目录下)和 SoVITS 模型(SoVITS_weights 目录下)了,我不用管模型文件在哪儿,WebUI 刷新后我们就能看到了。
在整个训练过程中,GPT-SoVITS 主要学习的,就是你的声音的音色,音调,语速,情绪。
声音推理
测试与推理:训练完成后,用一段新的文字测试你的模型。如果一切顺利,你应该能听到一个几乎和你一模一样的声音。
分享你的成果:最后,别忘了和你的朋友们分享你的成果。让他们听听,你的声音是如何被 GPT-SoVITS 完美克隆的!
第四部分:让 AI 用你的声音说话
各位,到了我们最期待的时刻——让 AI 张嘴说话!
WebUI
在上一部分,我们已经训练好了 GPT-SoVITS 所需要的两个模型,现在我们从页面中打开声音推理界面

打开之后,我们就能看到这个声音推理界面了
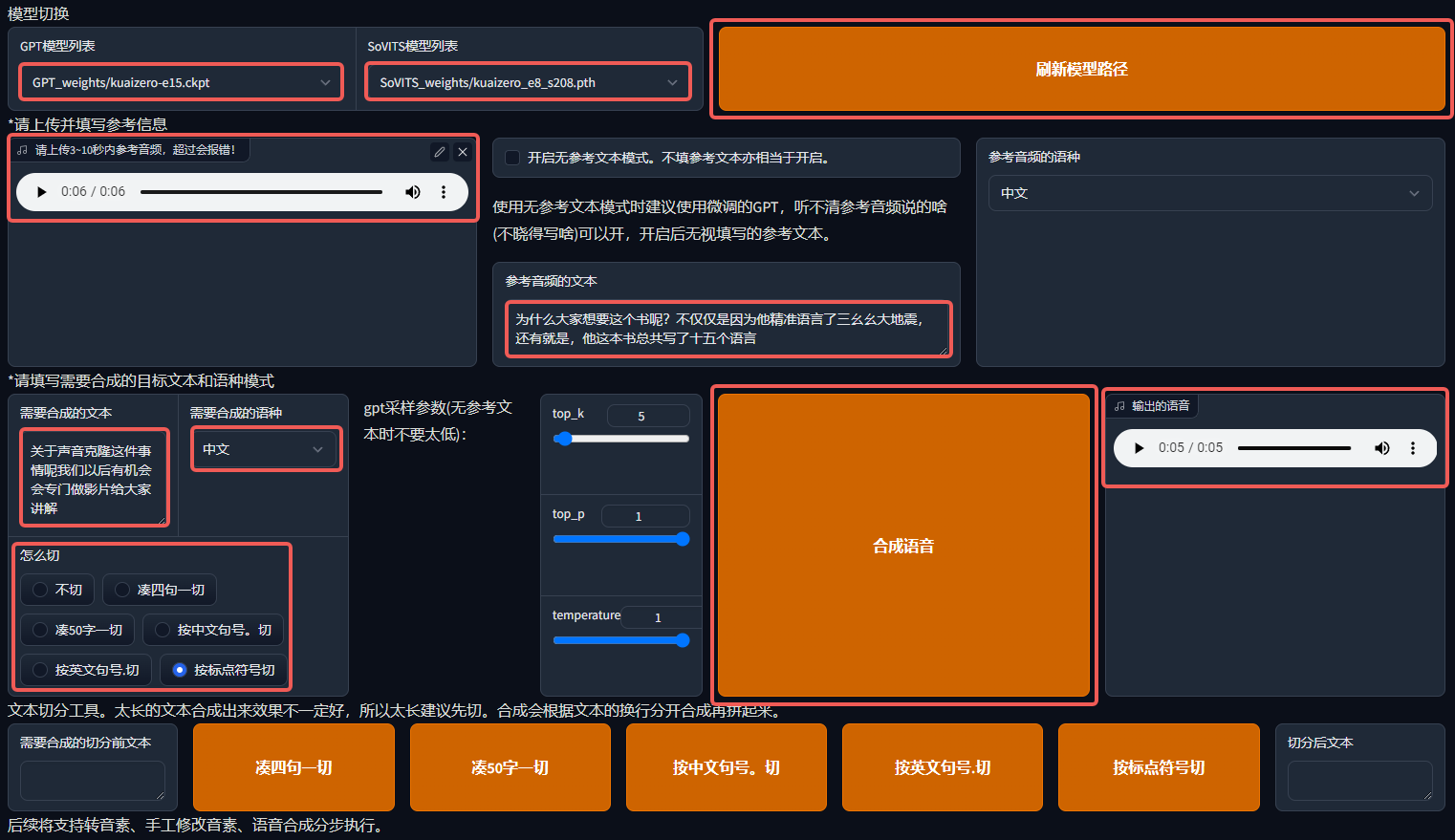
- 首先我们需要选择刚才训练的 GPT 模型和 SoVITS 模型,如果找不到就点击"刷新模型路径"就能出来了
- 然后我们还需要上传参考音频,这也是声音推理的依据,再配置参考音频的文本,让 AI 识别
- 最后我们填写需要合成的文本和需要合成的语种
- 点击"合成语音",我们就能得到 AI 用我们自己训练的模型合成的声音了!
其实我们也可以直接使用 pretrained_model 的 GPT 模型和 SoVITS 模型直接进行声音推理,但是经过训练之后的模型,声音的相似度会更高!
定制 GUI
也许你也发现了,我们每次声音推理,都需要从训练界面点击勾选再进入,其实大可不必,在 GPT-SoVITS 的根目录下,直接点击 interface_webui.bat 文件,就能启动推理界面!
如果你仍然觉得不方便怎么办?没关系,我们还可以自己定制化,因为它是基于 python 开发,那么我开发个自己的 GUI 界面,直接调用它的代码,也是可行的吧?
事实证明,的确可以,我基于原作者的接口,开发了一遍方便自己使用 GUI 界面,由于大多数参数我都使用默认,所以我把那些必要配置的参数提供了输入框,其他都是给了默认配置
作者本身也提供了 GUI 界面的方式,但是需要配置的参数太多了,不符合我希望快速进行声音推理的使用需求,所以我重新开发了界面
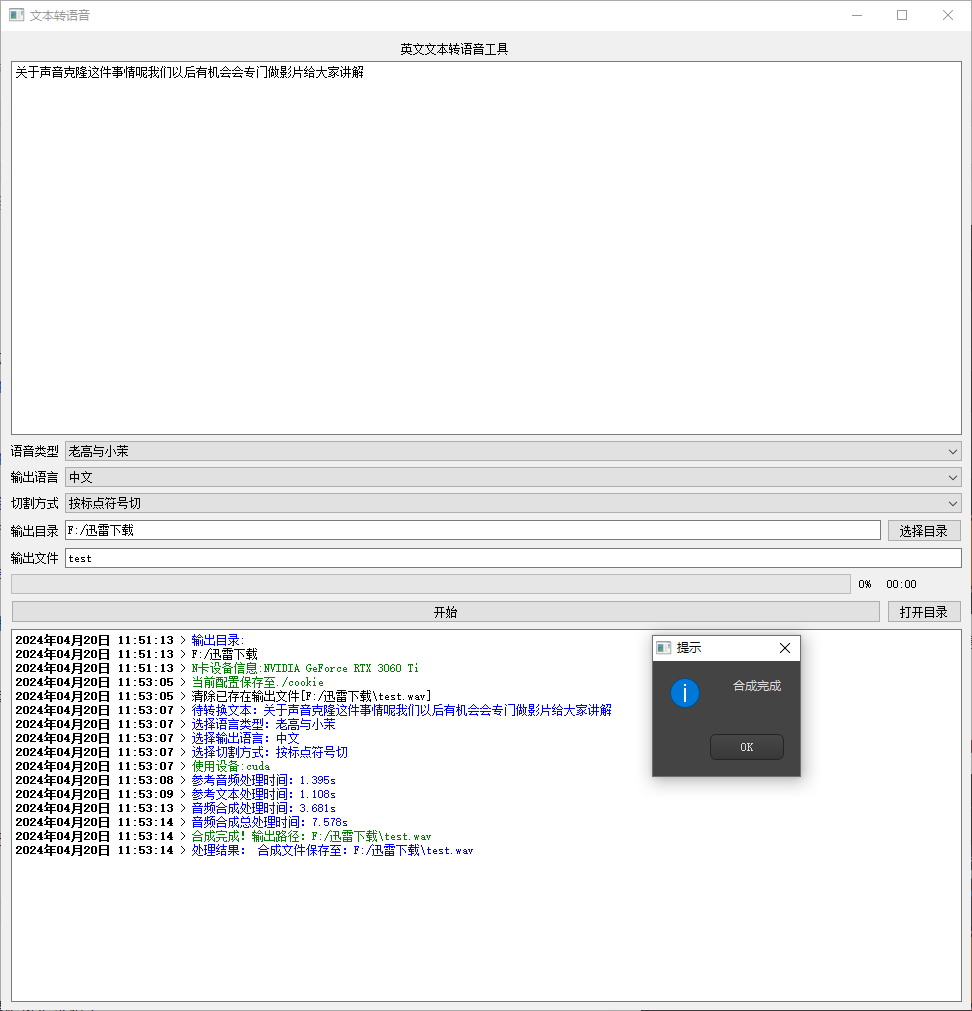
使用也非常方便,只需选择模型,填写文本,选择文本语种,就可以开始合成!如果需要新加模型,只需要 GPT 模型和 SoVITS 模型复制到对应目录,再改下配置文件,也能直接使用!
这样一来,我使用GPT-SoVITS就非常方便了,如果需要训练声音模型则使用原本的WebUI,否则直接打开我的GUI界面,简单配置参数就能进行AI声音能合成了
定制 GUI 是我个人开发,因此这里不多介绍,感兴趣的小伙伴,可以后台回复"声音合成GUI"即可获取,使用上的问题,也可直接联系我!
注意事项:
- 虽然 GPT-SoVITS 跟 StableDiffusion 相比,对硬件配置已经小了很多,但是仍然要求大约 4G 左右显存的 N 卡,否则它会切换到 CPU 来进行运算推理,使用 CPU 运算,其速度会慢到让你怀疑人生。
- AI 声音克隆,是一门技术,是技术就是双刃剑,本文所有内容,都仅供学习参考,请勿用于非法用途!
AI 声音克隆的无限可能
除了 GPT-SoVITS,还有很多工具都能实现 AI 声音的克隆和推理,AI 声音的未来也一定发展越来越快。
举个简单的例子,我们做个缝合:让 ChatGPT 来学习你的性格、习性、情绪等,成为一个没有肉体和外在的 AI 克隆体;让 Stable Diffusion、MJ 或还未面市的 Sora 来学习你的身材、样貌等,成为一个只有外在的克隆体,最后我们补上最后一环,用 GPT-SoVITS 成为你的声音克隆体。
一个只存在于数字世界的你就诞生了,它拥有和你一样的性格,一样的习性,一样的身材,一样的样貌。那么,它,是你吗?(突然上升到哲学高度)
我们不妨再大胆的想象,既然能完全克隆一个人,那么我们是否可以“复活”亲人,让亲人以数字克隆人的身份陪在我们身边?这个问题,留给你们去思考!
好了,今天的分享就到这里,我们鼓励大家都亲自去尝试各种 AI 工具和技术,尝试一下今天介绍的 GPT-SoVITS,体验声音克隆的魅力。欢迎在评论区分享你的体验故事!
别忘了关注我们,获取更多 AI 科普知识、技术教程和最新动态。让我们一起走在科技的前沿,探索 AI 的无限可能。
资源获取
GPT-SoVITS整合包:公众号后台回复“声音克隆整合包”
个人定制GUI界面:公众号后台回复“声音合成GUI”
资源获取
GPT-SoVITS整合包:
https://pan.baidu.com/s/1OE5qL0KreO-ASHwm6Zl9gA?pwd=mqpi
个人定制GUI界面:
链接:https://pan.quark.cn/s/88e13a3762b6 提取码:Te4C
Q.E.D.

