










AI绘画有各种各样的落地应用,之前我分享过如何使用Stable Diffusion来创作儿童绘本,从实现流程到最终变现的全过程,这里,我为大家分享另外一种AI绘图的变现方式——四维彩超预测
四维彩超预测不仅可以给自己或朋友的宝宝做,也可以给别人做来实现变现
本文针对四维彩超的宝宝长相预测的全流程解析,但是你仍然可以举一反三,技术是服务于生活的,你可以发现更多变现点!
一、爆点发现
在之前的文章已经分析过,小红书,是一个女性用户群体量很大的平台,其中很大一部分是孕妈或备孕的女性,即便都不是,也可能是未来想要宝宝的女性。那这部分人群大概率都会经历一个事情,就是做四维彩超。而这部分人群,很大一部分,是很想知道自己未来的宝宝长什么样的,他们也极有可能愿意为止付费。
这些群体,搭配上现在AI绘图技术,需求点就这样产生了——通过四维彩超预测宝宝未来长相
为了避免引流嫌疑,所有账号相关信息都做了处理
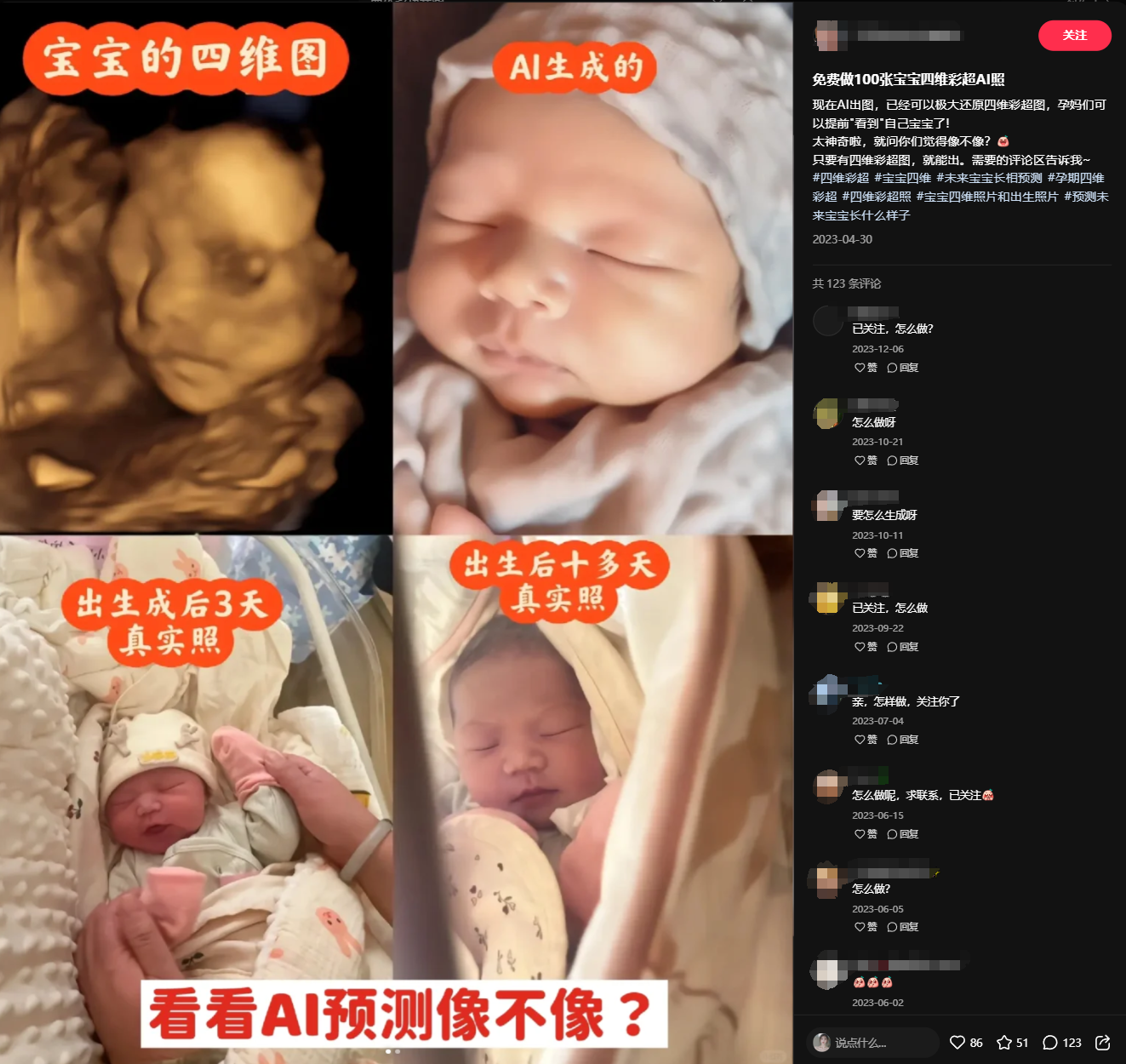
我们在小红书能发现,有很多这类的四维彩超预测宝宝长相的相关笔记
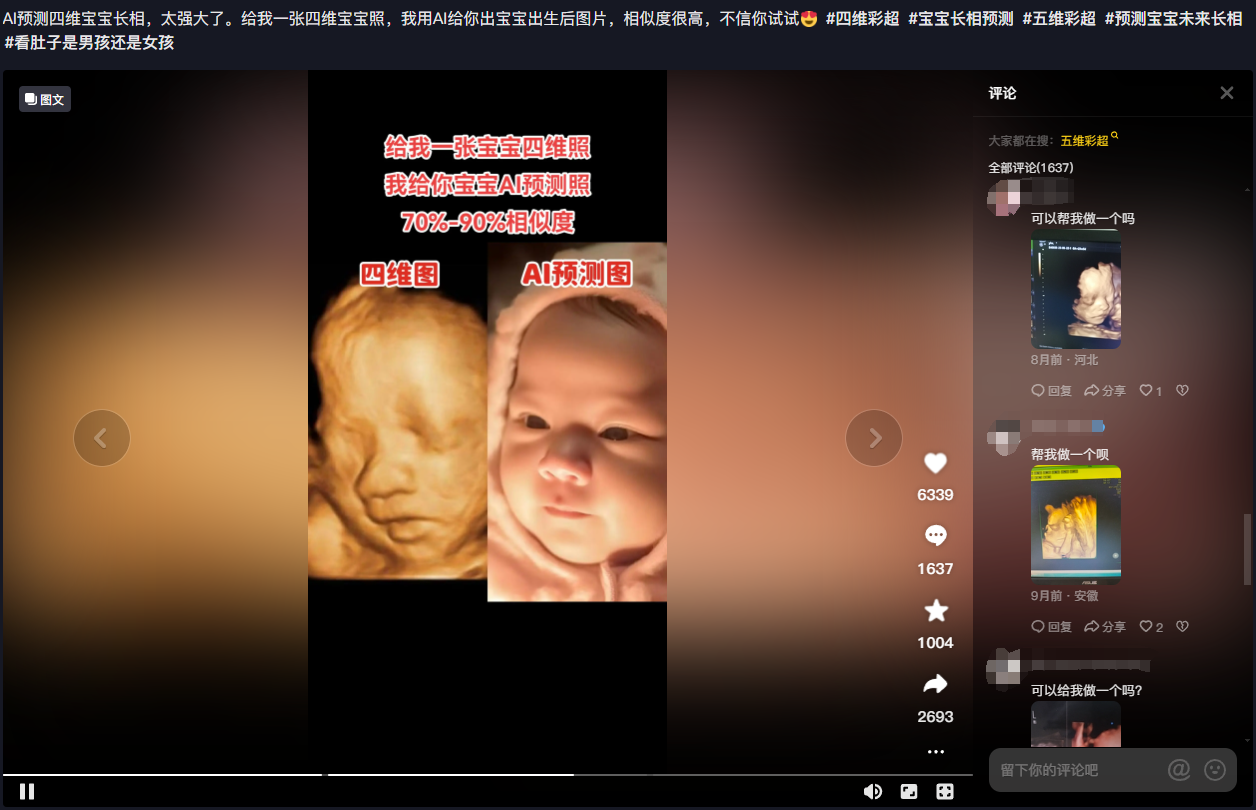
抖音相对要少一点,但是相对来说也有很多这样的视频
除了内容平台以外,我们可以在淘宝、拼多多、微店等电商平台,也能搜到大量的类似服务
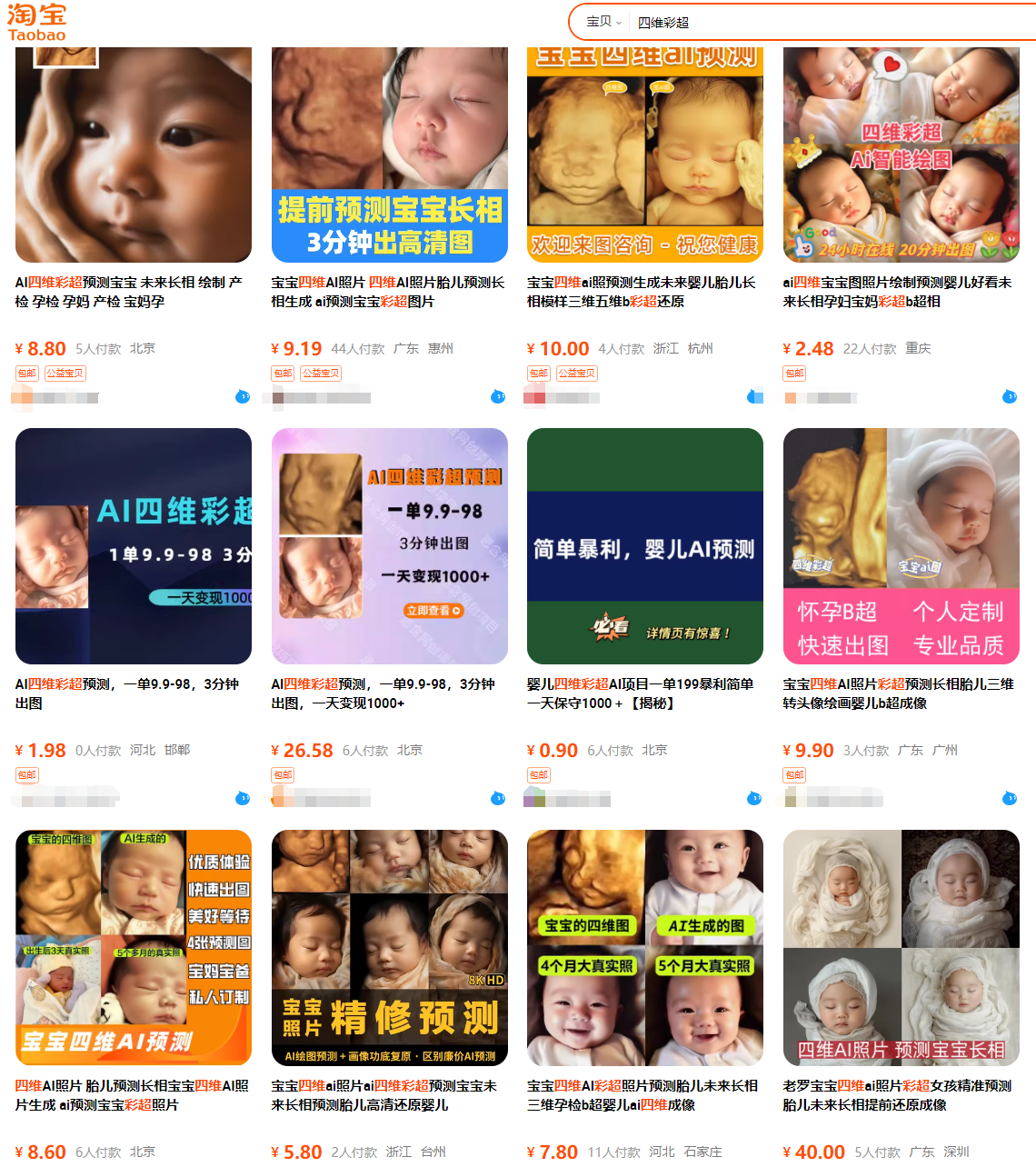
总得来看,这类的内容,点赞量和粉丝量都不一定高,但是评论数却很高,且评论内容大多是“能不能帮我做一个?”,“怎么收费?”,“怎么做?”,这也可以称之为异常值。这恰巧能说明,有这方面需求的群体还是很多的,这时候你要做的就是通过这类群体进行变现!
二、实现方式
我们就从技术层面,先为大家拆解四维彩超预测宝宝长相的制作流程
第一性原理
我们先抛开问题看本质——AI通过宝宝的四维彩超预测长相,它的原理是什么?
其实我在之前的一篇文章中提到过,但没有展开说,那就是照片的风格转换重绘。
对,没错,AI做的事情仅仅是根据你的四维彩超图像提供的宝宝的大致轮廓,然后通过AI自己的理解绘制的宝宝长相。
所以从原理上来讲,没有什么百分百的相像,都是概率问题!
哪有什么预测,不过是AI根据现有数据,和你提供的参考图,进行自己的绘制而已!
那换成AI绘图中的常用语,就是图生图!
要用AI进行图生图重绘,工具有很多,这里我分别以Midjourney和Stable Diffusion这两个最常见的AI工具来讲解实现步骤
Midjourney
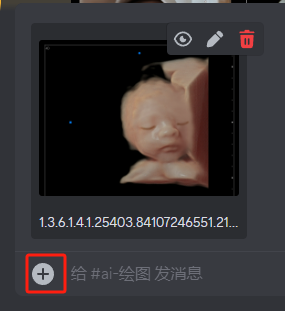
1.上传四维彩超
点击下方加号按钮,上传自己的四维彩超照,虽然是让AI预测,但是也尽量选择轮廓清晰的照片
2.编写提示词
以下是一个四维彩超的提示词模板,右键你上传的图片,复制链接地址,然后填入提示词中。提示词内容就是大致描述一下婴儿的一个表现状态即可,如果出的图不满意,再对提示词进行微调,最后中达到满意的效果
https://s.mj.run/xxxx super cute Chinese newborn baby,front face view,wrapped in a white blanket,falls asleep in peacefully, blemish, porcelain, face, talland pointed nose, thin and pink lips, serene, expressive facial, --ar 1:1 --s 250 --v 6.0
3.抽卡生成
最后就是抽卡生成了,mj毕竟还是ai生成,存在一定的概率问题,你需要在多次抽卡中找到最满意的一张
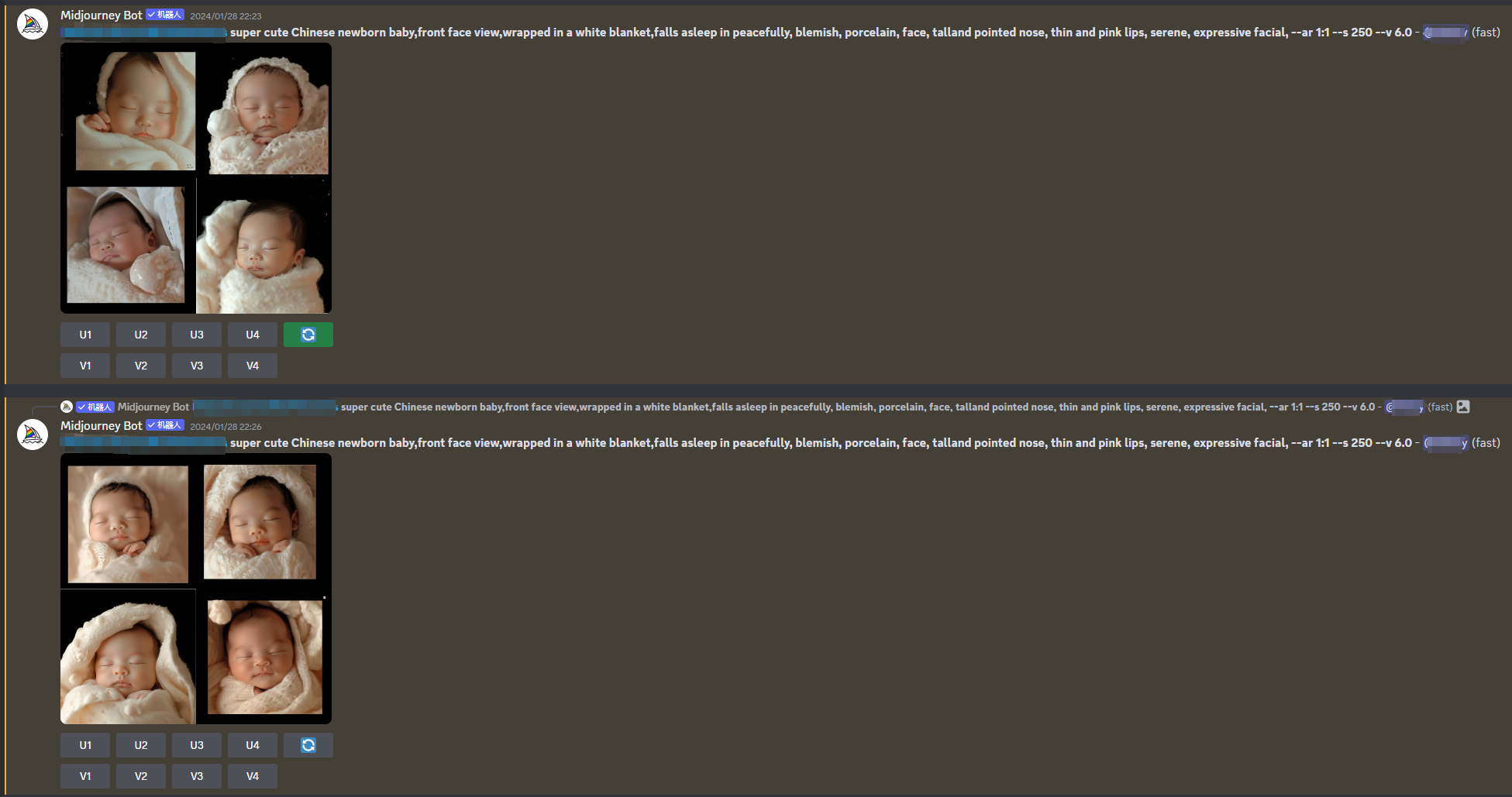
没错,Midjourney的整体实现过程就这么简单!不过需要注意的是,Midjourney相对来说,可能比较放飞自我,基本都是靠AI自己的理解在绘图,如果要求表情、姿态等跟原图相似,那可能还是需要控图能力更强的Stable Diffusion
Stable Diffusion
Midjourney还只能靠AI自己来控制图片细节,Stable Diffusion因为有ControlNet的存在,相对来说控图会更容易。这里我分别以界面更友好的WebUI和对工作流更友好的ComfyUI分别讲解。
无论是使用WebUI还是ComfyUI,我提供的大致思路都是基本的提示词文生图+ControlNet控图的方向来生图
WebUI
提示词插件
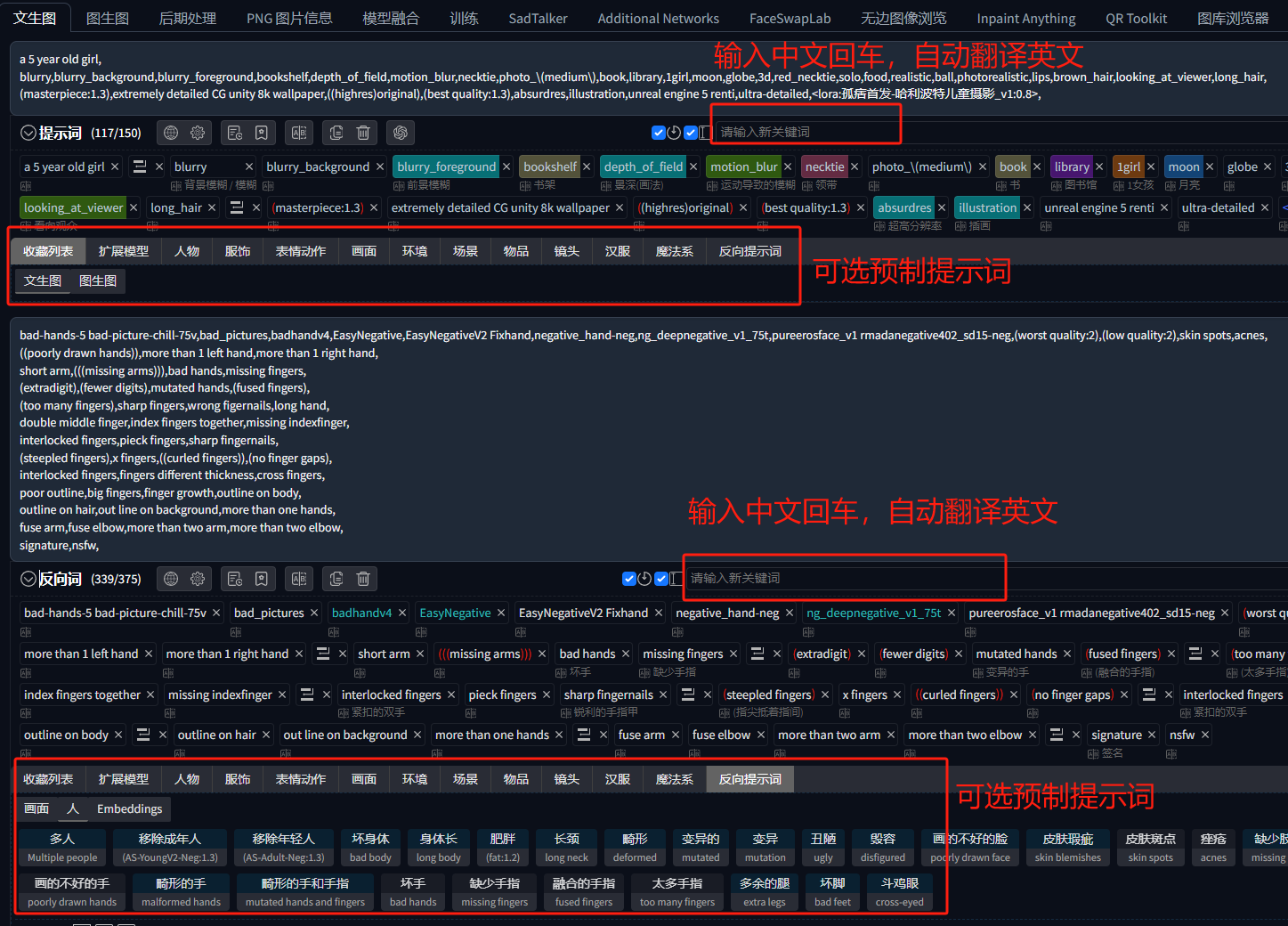
之前有小伙伴有疑问,你们写提示词是靠翻译软件吗?这里,我强烈推荐一款提示词插件“prompt-all-in-one”,有了它,你不再需要新打开一个翻译软件,一边想提示词,一边翻译英文,这对于英文不好的小伙伴十分友好!
使用它有以下几点优势:
- 输入中文后回车,自动翻译为英文加入到提示词框
- 对所有提示词都有归纳整理,可以非常方便的删除、临时删除、临时打开、加权重、减权重等
- 提供大量预制的提示词,可以直接选择想要的提示词来出图
安装方式可以通过插件商店搜索“prompt-all-in-one”或通过git仓库地址“https://github.com/Physton/sd-webui-prompt-all-in-one”安装
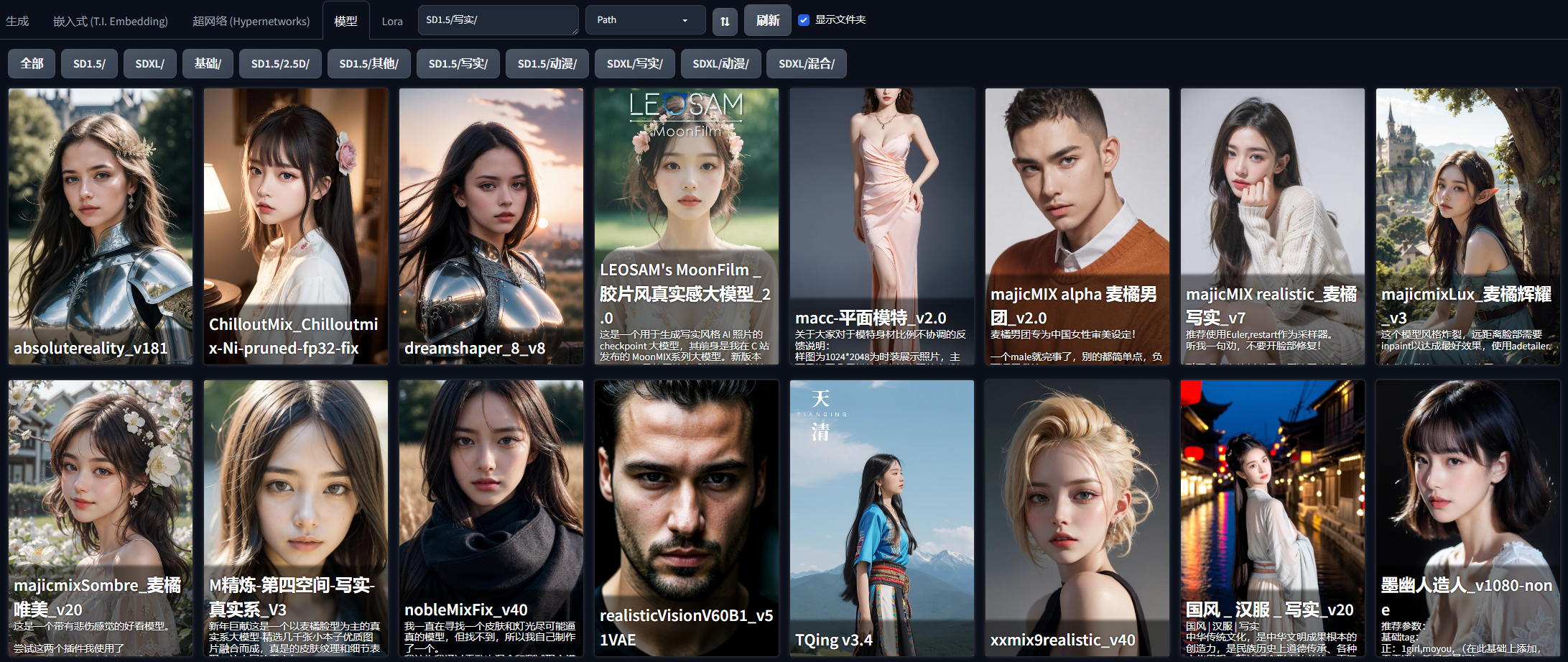
1.选择模型
在大模型的选择没有特殊注意的,只要是写实模型应该都问题不大,我亲测下来,majicMIX realistic 麦橘写实和墨幽人造人出图的效果都还不错
另外,为了保证更好的婴儿效果,也推荐几个适合婴儿的Lora模型,配合大模型使用效果更佳!

2.编写提示词
Stable Diffusion跟Midjourney使用的提示词稍有区别,因为我们需要基于ControlNet来进行生图,那么基本上使用的是SD1.5的模型算法,SD1.5的算法对于提示词的解析力(主要自然语言处理能力)是不如Midjourney的,在Midjourney的一句自然语言,在SD1.5中,我们需要拆解成多个单词,才能更容易被SD理解(这种情况在SDXL模型有很大改善)。
以下是我的四维彩超提示词模板
正向提示词
(A newborn Chinese baby:1.2),eyes closed,closed eyes,closed mouth,white skin,one-day-old baby,simple background,(hide hands:1.2),(no hands:1.2),black background,no teeth,<lora:新生 _ 婴儿写真_V1.0:0.3>,
(best quality:1.2),(masterpiece:1.2),(realistic:1.3),
负向提示词
too many fingers,fused fingers,missing fingers,bad hands,mutated hands and fingers,malformed hands,poorly drawn hands,mutation,extra arms,extra limb,mutated hands,disconnected limbs,floating limbs,malformed limbs,missing limb,cross-eyed,bad feet,extra legs,poorly drawn face,skin blemishes,skin spots,(((blur))),(EasyNegative:1.2),ng_deepnegative_v1_75t,paintings,sketches,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),bad anatomy,DeepNegative,(fat:1.2),facing away,looking away,tilted head,lowres,bad anatomy,bad hands,text,error,missing fingers,extra digit,fewer digits,cropped,worstquality,low quality,normal quality,jpegartifacts,signature,watermark,username,blurry,bad feet,cropped,poorly drawn hands,poorly drawn face,mutation,deformed,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,extra fingers,fewer digits,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,text,error,missing fingers,missing arms,missing legs,
其中我使用了一个婴儿写真Lora,目的是为了更好的生成婴儿形态,这个根据实际情况酌情添加
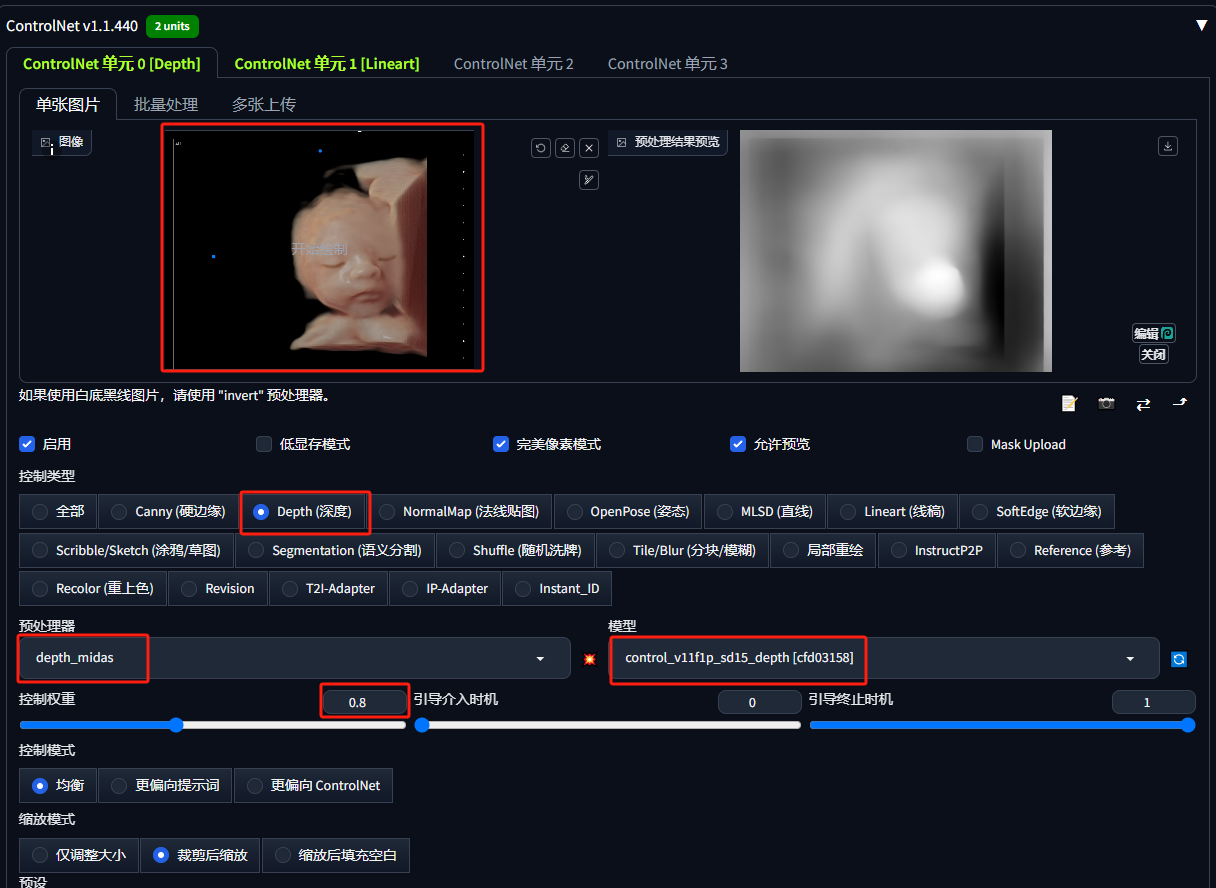
3.上传四维彩超照到ControlNet0
和Midjourney同理,我们尽量选择线条轮廓清晰的四维彩超图像
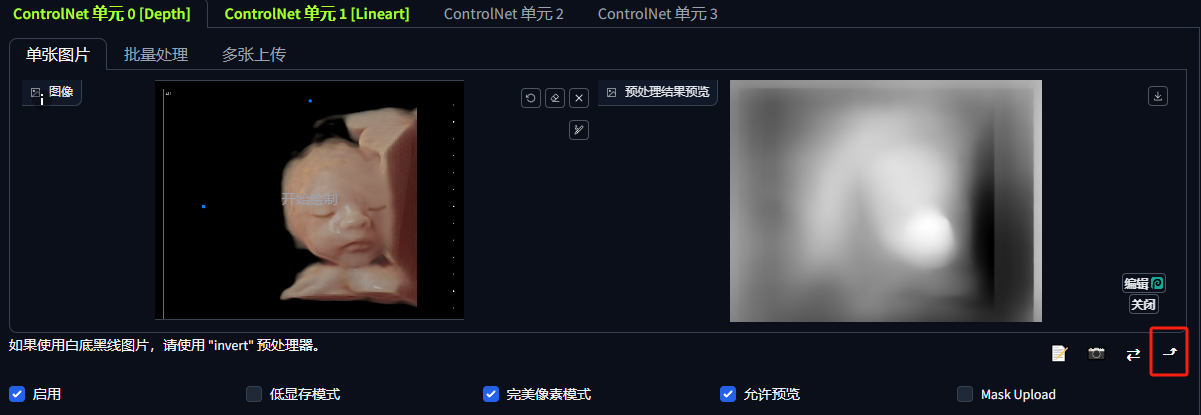
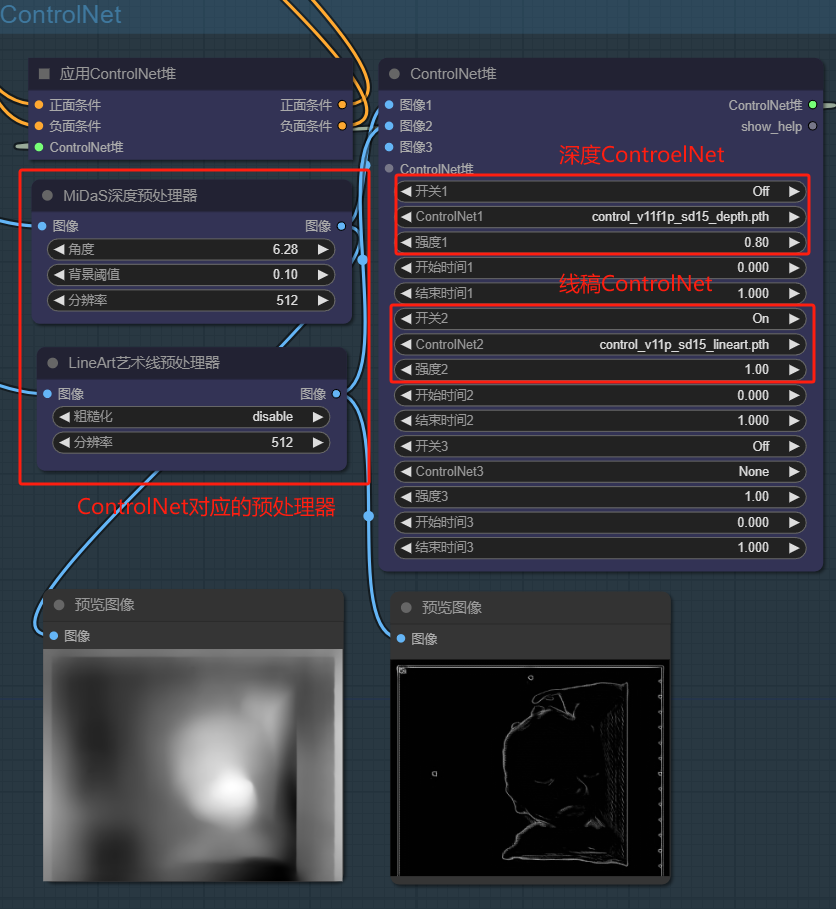
这里使用深度ControlNet,目的是让婴儿和背景有个明显的层次关系。这一步可以根据实际测试情况选择关掉,效果可能更好
- ControlNet选择Depth(深度)
- 控制权重选择0.8
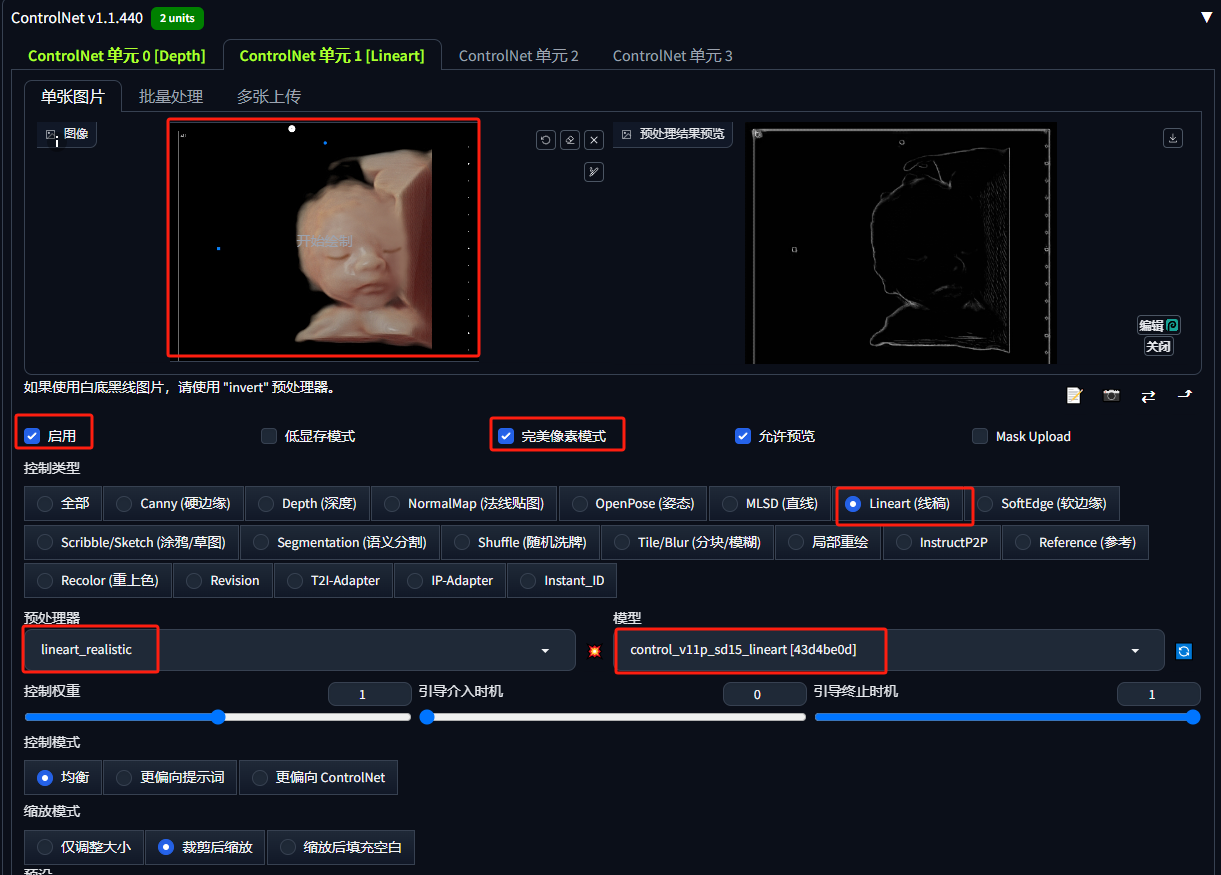
4.上传四维彩超照到ControlNet1
这里使用线稿ControlNet,目的是控制婴儿的整体的线条轮廓
ControlNet选择Lineart(线稿)
控制权重默认1
注意:如果你的四维彩超图,实在是线条太混乱,这里生成的线稿你可以单独做下处理,只保留你希望保留的轮廓即可!
5.设置图片尺寸
一般来说,我希望的是它和我们提供的四维彩超图的尺寸一直,只需点击ControlNet下面这个小图标即可快速同步尺寸(如果尺寸过大,需要等比例缩小,否则可能爆显存)
6.设置其他参数
- 采样方法:DPM++ 2M Karras(写实一般采用此方法)
- 迭代步数:30
- 总批次数:9(批量抽卡)

7.抽卡生成
一切准备就绪,就开始抽卡吧

很明显,我们抽出来的卡中,大部分都是各种怪异畸形,但是一定会有那么一两张能用的,根据经验说,一般在提示词让宝宝隐藏手,或者整个身体包裹起来,只能看见脸,这样的效果是最好的,比如在上面这次九连抽,第二排的最左边那张的整体效果就是最好的。
如果一轮都是畸形,那就再抽一轮!
ComfyUI
其实WebUI会了,那在ComfyUI中实现就大同小异了,基本步骤也都相同,我就不再细说。
1.选择模型
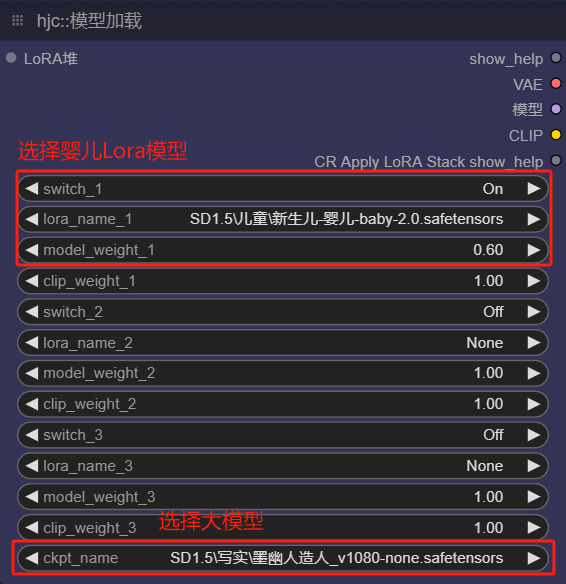
这里的婴儿Lora权重和WebUI调整的不一样,这是我根据实际出图效果调整的,Lora权重,用哪个Lora,甚至是否需要婴儿Lora,都需要边看效果边调整
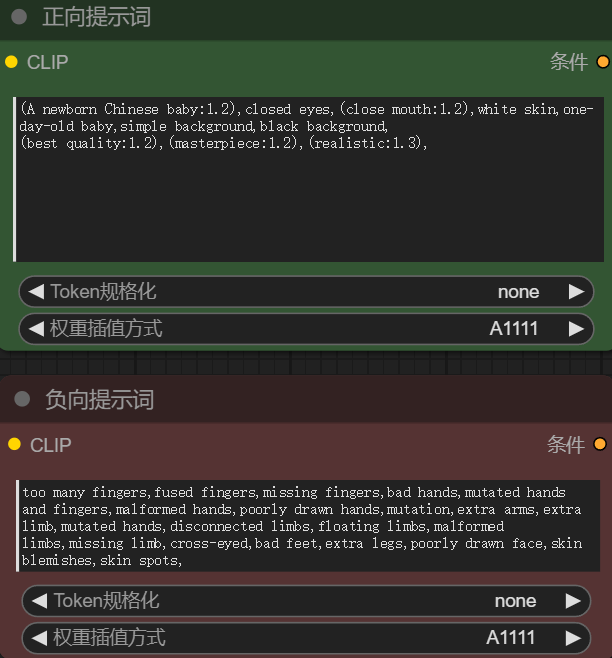
2.编写提示词
3.ControlNet应用堆
不同于WebUI的多个ControlNet串联,在ComfyUI中一般使用一个ControlNet应用堆即可,配置多个ControlNet再根据需求来开关不同的控制模型。
这里我关掉了深度控制模型,是因为在实际测试中,发现去掉深度模型效果更好
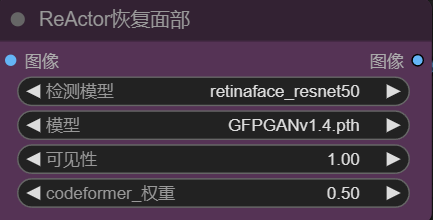
4.面部修复
在WebUI中,一般默认都是打开了面部修复的(设置->系统设置->面部修复),在ComfyUI中要实现同等效果,需要添加面部修复节点,主要是需要使用codeformer或GFPGAN来进行修复(实测使用GFPGAN效果更好)
5.其他参数
- 采样方法:dpmpp_2m_sde
- 调度起:karras
- 迭代步数:50
- 总批次数:9(批量抽卡)
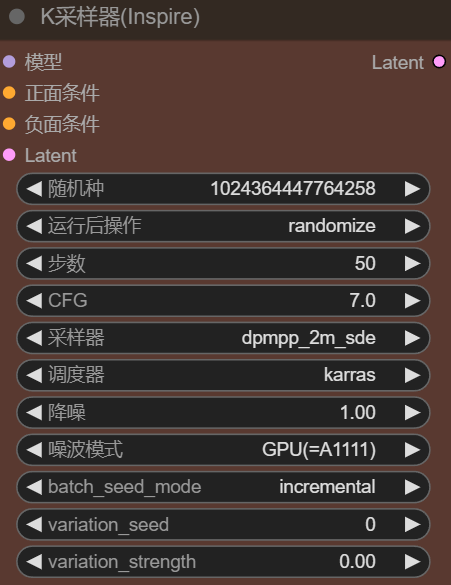
以上参数于WebUI稍有不同,也都是经过实际测试得到的最佳参数
6.抽卡生成
接下来就是激动人心的抽卡环节了!

不得不说的是,在ComfyUI中的抽卡成功率比WebUI要高,这也很有可能是二者的实现算法逻辑的区别所造成。在这一轮的九连抽中,大部分的图都是可用的!
文末分享四维彩超ComfyUI工作流
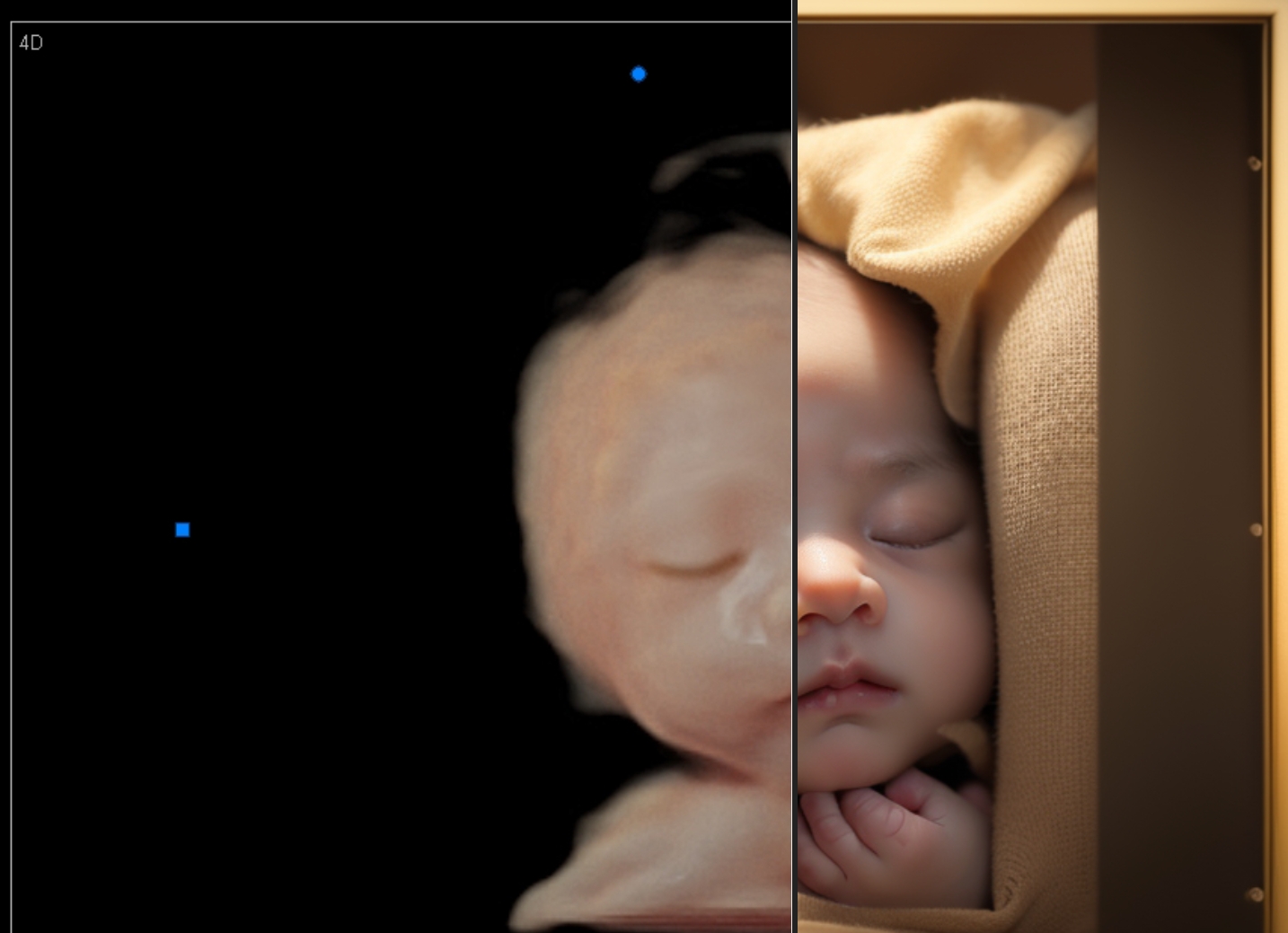
对比图
做完之后,我们可以再做一张对比图,你把对比图发给对方,对方会更加觉得你的效果做的不错
三、如何变现
看到这里,你已经掌握了根据四维彩超进行宝宝长相预测的技能了,那么它如何能变现呢?
1.吸引流量
首先,当然还是需要先先做一些案例发到内容平台,先要有内容,别人才能知道你能做这些。至于如何让你的内容让更多的人看到,就需要一些小红书或者抖音的运营经验了
举例
- 小红书可以以妈妈的视角“原来我的宝宝以后长这样!”,再打上一些四维彩超,孕妈,宝宝等一些标签
- 抖音则可以做一个类似卡点换图的效果,再配上音乐
不同平台有不同的运营方式,这个就要因地制宜了
2.代做预测图
这个就很好理解了,有了流量,一般就会有大量代做需求找上门了,一张多少钱,三张多少钱,五张多少钱,你就可以开始有偿定制了。这也是四维彩超预测图的最基本的变现模式。
3.母婴羊毛群
相信我,孕妈的消费能力是你无法想象的,如果你只是让他们为你的四维彩超预测图付费,就太浪费了。这些客户都是母婴产品的潜在客户,你完全可以把这些人拉群,然后通过佣金平台分销母婴产品,他们购买,你赚佣金,这不是开启印钞机模式?
总之,你只要抓住孕妈强大的消费能力,和对未来宝宝的长相的好奇这两个点,具体变现方式,你完全可以自由发挥了~
四、资源
四维彩超预测ComfyUI工作流
链接:https://pan.quark.cn/s/0c8d0c594cd5
提取码:BKiv
关于如何利用AI预测宝宝未来长相进行变现的全流程,就解读完了,其中有不少细节我没有展开讲,后续会对其中部分技术做更详细的拆解,欢迎关注我后续文章!有任何问题也可以在评论区留言!
Q.E.D.

