










玩AI这么久,生成AI美女的技术你是越来越熟练了,但是它也不会动呀!这时候,你是不是经常会想,如果它能开口说话就好了?
** 好的,那今天我们就让你的AI老婆开口说话!**
现在AI的发展让赛道越来越多了,从ChatGPT这样的对话式AI,到SD、MJ这样的图像生成式AI,甚至Sora这样的王炸级别的视频生成AI,AI工具和技术以肉眼可见的技术飞速生长,其中就有一项技术,也许你听过,甚至你可能见过,那就是数字人。
什么是数字人
数字人,也被称作虚拟形象或虚拟角色,是一种通过计算机生成的、具有人类特征的三维模型。它们可以用于娱乐、教育、广告、社交媒体等多种场景,并且能够进行交互和模拟人类行为。数字人可以是完全虚构的,也可以是基于真实人物的数字化复制。
数字人现在广泛应用于口播、短视频、虚拟主播、虚拟偶像、直播带货等,并且未来也有很多的应用前景。
怎么创造一个数字人
现在市面上常见的数字人工具有很多,常见的有以下几款
1.heygen
https://www.heygen.com/
这是目前使用效果最好的数字人创作工具,现在看到很多效果很好的数字人,基本都是用heygen生成的,它的使用范围非常广,且效果逼真,主要用于克隆自己的数字人。很多时候如果不告诉你,你可能都很难发现这是数字人。
不过这个价格嘛,em~,土豪不用犹豫,请直接购买!
以下是Heygen的数字人效果
https://resource.heygen.ai/homepage/homepage_joshua.mp4
2.腾讯智影
https://zenvideo.qq.com/
腾讯智影,算是腾讯出的比较早的数字人工具了,效果也还算不错

不过这个价格,也是不便宜的
3.剪映
剪映作为国内最流行的短视频剪辑软件,也添加了数字人功能,不过暂时还不支持用户克隆自己的数字人,且很多是vip功能
4.阿里EMO
https://github.com/HumanAIGC/EMO
阿里EMO是前段时间推出的,能通过一张图片,就能让人物说话唱歌,并动起来,效果非常好,可惜github上只有一份README,只能看到效果,并未开源(我猜测未来开源的可能性也不大)。
好消息是,现在通过通义千问APP,输入“emo”,已经可以体验EMO的效果了
以下是EMO的数字人效果
http://vd3.bdstatic.com/mda-qbu07289k3xs26yu/360p/h264/1709165334134227873/mda-qbu07289k3xs26yu.mp4
5.腾讯AniPortrait
https://github.com/Zejun-Yang/AniPortrait
腾讯开源数字人工具,EMO的竞品,同样是一张照片转数字人视频。总体来看,效果上不如EMO,但是也非常棒,胜在开源,比如阿里EMO的一份README强多了
AniPortrait还有针对ComfyUI的插件可下载,感兴趣的同学可以自行尝试,本文不详细介绍
地址:https://github.com/frankchieng/ComfyUI_Aniportrait
并且他还有在线体验地址:https://huggingface.co/spaces/ZJYang/AniPortrait_official
AniPortrait虽然开源免费,且可以本地部署,但实际体验下来,对本地配置还有一定要求,才能达到最佳效果
SadTalker
介绍这么多工具,都各有优缺点,有的对本地配置要求高,有的使用有限制,有的不能定制化克隆,有的什么都好,就是贵(当然了,贵可能不是它的缺点,是我的缺点)
那怎么办呢,没钱就不能体验数字人了吗?当然不是!这里我介绍一个开源免费,本地部署,且配置要求没有那么高的数字人工具——SadTalker
SadTalker是比较早的数字人工具,最近一次更新也是7个月前了,但是目前来看,效果依然很不错,未来也很有前景,等待作者的持续更新!
1. 安装
SadTalker有两种界面运行方式,一种是独立安装,单独启动;一种是作为StableDiffusionWebUI的插件运行
首先确认我们安装了python环境,推荐版本3.8-3.10,https://www.python.org/downloads/release/
并且推荐在SadTalker目录下创建python虚拟目录python -m venv venv
独立安装
下载代码仓库:https://github.com/OpenTalker/SadTalker.git
我们可以通过git clone https://github.com/OpenTalker/SadTalker.git命令来下载代码仓库,或直接通过下载地址https://github.com/OpenTalker/SadTalker/archive/refs/heads/main.zip 来下载并解压得到代码仓库
SD插件安装
通过StableDiffusion的插件安装有两种方式,分别是通过插件商店安装
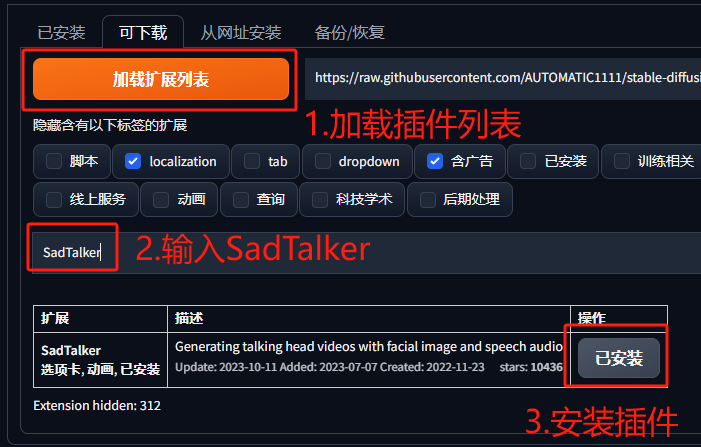
或直接输入代码仓库地址安装:https://github.com/OpenTalker/SadTalker.git

安装完成之后,重启Stable Diffusion就可以看到SadTalker页签啦
启动WebUI
通过SD插件安装的方式,重新启动即可通过SadTalker页签进入,单独安装则需要启动webui.bat
看到控制台输出地址后,既可以通过网页访问了
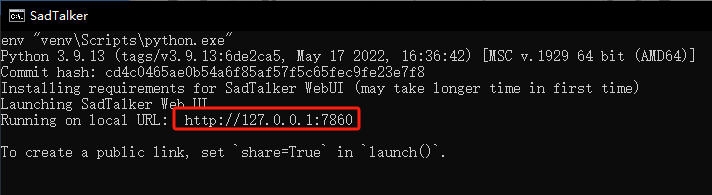
2. 图片源
SadTalker需要上传一张图片作为源图片,当然这个图片无论是真实照片,还是AI生成图片,都是可以的。
不过对于SadTalker来说,照片尽量选择大头照为宜
3. 音频源
同样的,音频源可以是自己录制的声音,也可以是由AI生成的声音
推荐使用ElevenLabs(https://elevenlabs.io),或用剪映生成
当然,也可以参考我之前介绍过的GPT-SoVITS的克隆声音来制作声音
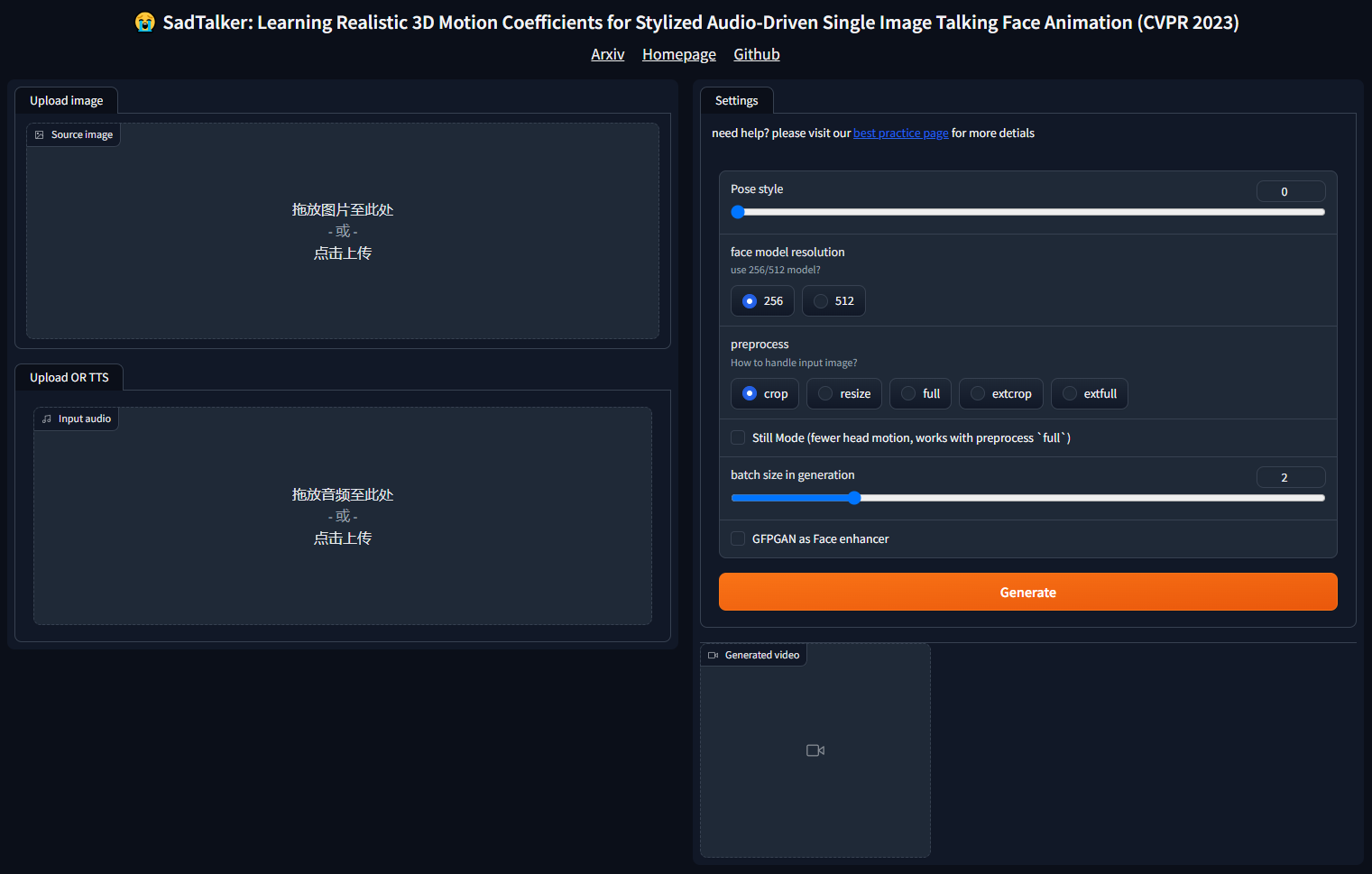
4. 调整参数
对于WebUI界面来说,可调参数不是很多,因此上手也算比较容易
- pose style:选择姿势有0-45可选
- face model resolution:选择脸部渲染时使用256或512尺寸
- preprocess:预处理方式crop(裁剪到只剩头部)/resize(对图片重新定义尺寸)/full(全尺寸)/extcrop(额外裁剪)/extfull(全尺寸)
- Still Mode:是否让头部更少运动,只在使用full预处理时生效
- batch size in generation:批量处理数量,GPU越好可以拉的越高,处理速度越快
- GFPGAN as Face enhancer:是否进行脸部增强,优化脸部处理
5. 合成视频
一切准备就绪后,我们就可以开始合成数字人视频了,点击“Generate”,然后等待即可,时间长短根据音频长度,以及配置有关,一般来说在几分钟就能完成。
6. 使用命令行
到这里为止,我们已经可以使用SadTalker来生成数字人视频了,大部分网上能搜到的教程也就到此为止了。
但是在这里,我将为大家带来SadTalker更多的参数调整方式,来达到更好的效果!
但是如果你仔细看过SadTalker在github的README,你可以知道,它其实很多很多可调参数,调整不同的参数,能生成的视频效果更好。
对于程序员朋友来说,直接调用python代码,并传入更多参数,这个过程一定不陌生,为了照顾大家,我大概说在怎么通过命令行来直接调用SadTalker
首先打开命令行,通过win+r输入cmd或开始菜单中打开命令行黑窗口界面

然后通过cd命令进入到SadTalker所在目录(目录地址以你的为准)
然后使用python命令调用inference.py文件,不过需要注意的时候,这里用的Python需要和你在webui.bat中用的python一致,也就是说,如果你创建了venv的虚拟环境,则需要使用虚拟环境下的python,比如我这样:

这样,我们就可以直接通过调用inference.py来生成数字人视频了
这样做,有什么好处呢?
我们可以看到之前的界面上,可调参数并不是很多,很容易上手,但是如果我们需要实现更好的效果,还需要加一些关键的参数。关于SadTalker提供给我们的可调参数,我都列这里了
| 参数名 | 默认值 | 说明 |
|---|---|---|
| driven_audio | ./examples/driven_audio/bus_chinese.wav | 驱动音频地址 |
| source_image | ./examples/source_image/full_body_1.png | 源图片地址 |
| ref_eyeblink | None | 眨眼参考视频地址 |
| ref_pose | None | 姿态参考视频地址 |
| checkpoint_dir | ./checkpoints | 模型输出地址 |
| result_dir | ./results | 生成视频输出地址 |
| pose_style | 0 | 姿态类型0-45 |
| batch_size | 2 | 脸部渲染批量处理数量 |
| size | 256 | 脸部渲染图片尺寸大小 |
| expression_scale | 1. | 表情丰富程度 |
| input_yaw | None | 调整头部角度 |
| input_pitch | None | 调整头部角度 |
| input_roll | None | 调整头部角度 |
| enhancer | None | 脸部增强[gfpgan/RestoreFormer] |
| background_enhancer | None | 背景增强 [realesrgan] |
| cpu | 使用CPU推理 | |
| face3dvis | 生成3d渲染脸部 | |
| still | 裁剪回原始视频的全身动画 | |
| preprocess | crop | 预处理方式 [‘crop’/‘extcrop’/‘resize’/‘full’/‘extfull’] |
| verbose | 是否保存中间输出 | |
| old_version | 使用pth模型而不是safetensor模型 | |
| net_recon | resnet50 | [‘resnet18’/ ‘resnet34’/‘resnet50’] (废弃) |
| init_path | None | (废弃) |
| use_last_fc | False | zero initialize the last fc |
| bfm_folder | ./checkpoints/BFM_Fitting/ | bfm目录 |
| bfm_model | BFM_model_front.mat | bfm模型 |
| focal | 1015 | 对焦点 |
| center | 112 | 重点 |
| camera_d | 10 | 相机角度 |
| z_near | 5 | z轴近点 |
| z_far | 15 | z轴远点 |
举个例子,github的README中提供了这样的一个效果
https://github.com/OpenTalker/SadTalker/blob/main/docs/using_ref_video.gif?raw=true
那这个效果呢,其实是在使用SadTalker时,加入眨眼参考视频,我们很多时候生成的视频看起来有点假主要还是眼睛不怎么眨导致,那这个眨眼参考的模式能让生成的数字人更加自然和逼真
这里面有很多的参数,经过多次尝试我个人总结以下几个参数是比较重要的:
- driven_audio:这个就不用多说了,驱动音频一定是必不可少的
- source_image:同理,源图片也一定是必不可少的
- ref_eyeblink:添加眨眼的参考视频,可以让数字人的表情更逼真
- ref_pose:添加姿态参考视频,数字人的头部姿态会更加自然
- enhancer:脸部增强,这个选项一般都会勾选上,来增强人物脸部渲染
- size:脸部渲染尺寸,WebUI界面只提供了256和512两个选项,事实上部分情况也确实够用,如果你的显卡足够强,那么这个size可以更高
- preprocess:预处理方式决定了视频的景别是全身还是大头,不过有时候全身的衔接不自然也可以通过裁切为大头来解决
- expression_scale:脸部表情的丰富程度,这个需看情况多尝试了,表情的丰富程度需要在一个适度的值,默认值1效果就很不错了。
- still:如果是全身的预处理模式,配合still参数,可以更好的控制头部更少的运动,显得更加自然
- batch_size:默认2对于大部分显卡都适用,如果你的显卡稍弱就减小,你的显卡足够强就加大
以上的这些参数是能直接影响到生成视频的质量的,比如我通过以下的一行命令,引用Taylor的一段采访视频,再配合我用SD生成的Taylor的AI图,所生成的AI视频
venv\Scripts\python.exe inference.py --enhancer gfpgan --expression_scale 2 --preprocess resize --ref_pose "F:\movie\taylorref\taylorref.mp4" --driven_audio "F:\movie\taylorref\taylorref.MP3" --source_image "C:\Users\Administrator\Desktop\taylor_20240501003940.png"
总的来说,SadTalker还是更适合与人物说话是头部和表情都只有微弱变化的应用场景,大开大合的动作在目前看来效果会非常不自然(期待作者的更新),当然了,说到这,我还有点理解“SadTalker”的字面意思了:悲伤的谈话
7. 视频剪辑
最后,我们做出来了数字人视频,只要稍加剪辑,就可以做成一个短视频了。现在很火的一些语录口播、情感口播、AI复活等,其实都可以使用SadTalker做出数字人视频,再配合一些短视频的创作思路来使用。
关于SadTalker的使用讲解,到这里就差不多了,工具本身只能是工具,如何使用,还需要大家发挥自己的想象。文中提到AniPortrait,但没细讲,这也是新出的非常不用的开源数字人生成工具,关于这个,以后有机会我会再单独讲解,欢迎关注我!我会持续输出优质内容!
好了,既然你都看到这里了,那么就去尝试一下吧!用SadTalker做出你的第一个数字人视频!期待你们的成果!
特别声明:
每当遇到这样的AI技术产生的时候,我其实都会感到一些恐慌,网络上的内容越来越AI化了,我们普通人要如何判断和鉴别,如果本身对我们人身安全无害,那也无所谓,但如果有人有歪心思,想用AI侵犯了我们的人身财产安全,那我们就要提高警惕了。原先是短信可能是诈骗,后来是电话也能诈骗,现在视频都可能是诈骗了!作为普通人,我们在AI技术爆发的今天,也要提高自己的人身安全警惕意识;作为AI内容创作者,我们应该把AI技术用于正面方向,让社会向着积极的方向发展!
Q.E.D.

