










AIGC现如今可谓是如日中天,AI绘画算是其中最火的其中之一了。现在的AI绘图工具也是百家争鸣,不管是网页端,APP端,还是小程序端,都能看到各种各样的AI绘图工具,他们多是需要你发送关键词或绘图命令到他们的服务器,然后由服务器渲染完成之后返图给你,所以一定会占用他们的服务器资源
那么,显而易见,他们无一例外都有一个致命的缺点:要钱!
不可否认的是,这些工具的确可能调教的更容易上手使用,但是在这个开源的时代,当然是要自己部署一个AI绘图工具了!
今天,我就手把手带你免费部署本地AI绘图工具——Stable diffusion
什么是Stable Diffusion
stable diffusion是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像。它通过模拟扩散过程,将噪声图像逐渐转化为目标图像。这种模型具有较强的稳定性和可控性,可以生成多样化效果和良好视觉效果的图像。
说人话,就是它能稳定生成可控图像
Stable Diffusion能干什么
stable diffusion能生成图像这一大功能,又能主要细分以下小功能
- 文生图:通过正向提示词,负向提示词,以及模型选择,宽高,迭代步数,随机种子,等各种参数调节,生成你想要的特定图像
- 图生图:通过正向提示词,负向提示词,以及模型选择,宽高,迭代步数,随机种子,重绘幅度,参考图片,生成你想要的特定图像
- 后期处理:宽高调整,缩放,放大算法等
- 训练自定义模型:可以根据自己的喜好,训练出更有针对性,适用于自己的模型。
- 扩展:有丰富的扩展库,丰富绘图工具库,实现更多AI绘图功能。(如果你愿意折腾,你会发现更多的新大陆)
怎么安装部署
从github下载源码
可千万别从百度去搜索下载,百度搜出来的都是各种各样的广告,最后下载的一定是他们要你付费的版本。
正确的做法是打开github,进入stable diffusion的官方版本:https://github.com/AUTOMATIC1111/stable-diffusion-webui。
程序员同学,我就不赘述如何从github克隆代码下来了,非程序员同学也别害怕,它也可以像下其他软件一样直接下载,点击Code,然后点击Download ZIP即可下载,下好解压到你电脑的任意目录(建议SSD的目录下)
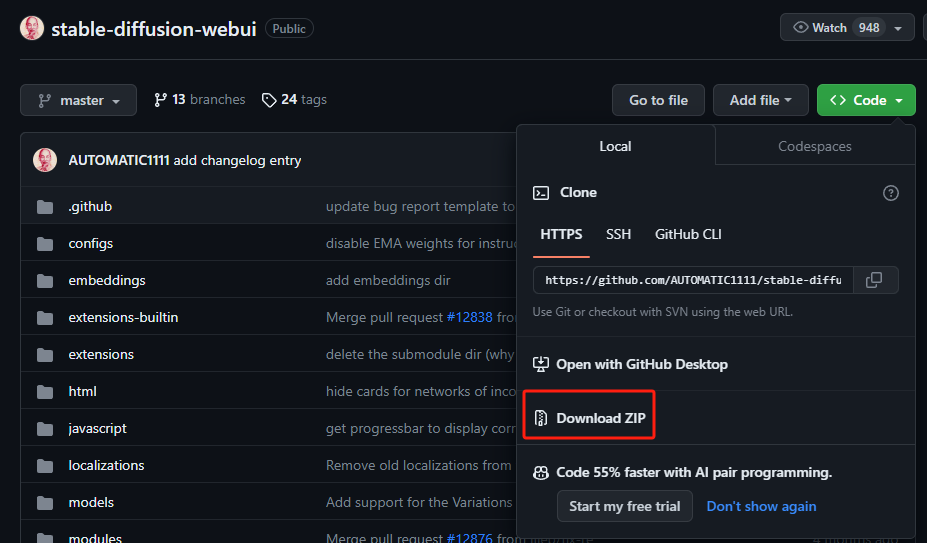
安装python环境
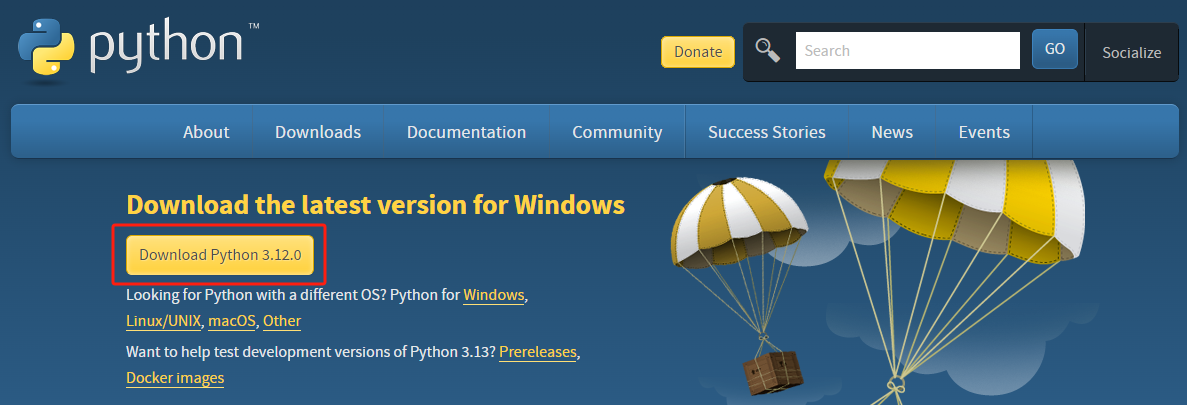
由于stable diffusion需要python运行环境,因此我们还需要安装python环境。
进入python官网下载:https://www.python.org/downloads/
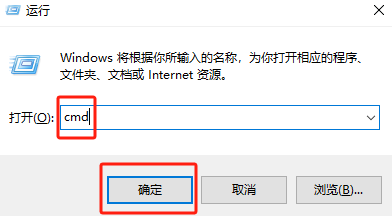
安装完成后,测试python环境是否安装好,使用win+r打开命令终端
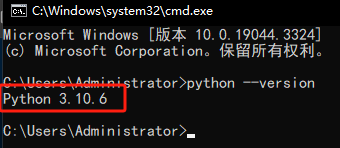
输入python --version,只要看到"Python 版本号",即安装成功
启动stable diffusion
运行解压出来的stable diffusion源码的位置的根目录下的webui.bat或webui-user.bat(其实也是调用webui.bat脚本),这时候会弹出来命令行终端,并开始刷新日志,当你看到以下日志则代表启动成功:
Running on local URL: http://127.0.0.1:7860

日志同时也输出了应用的地址,在浏览器打开即可
汉化界面
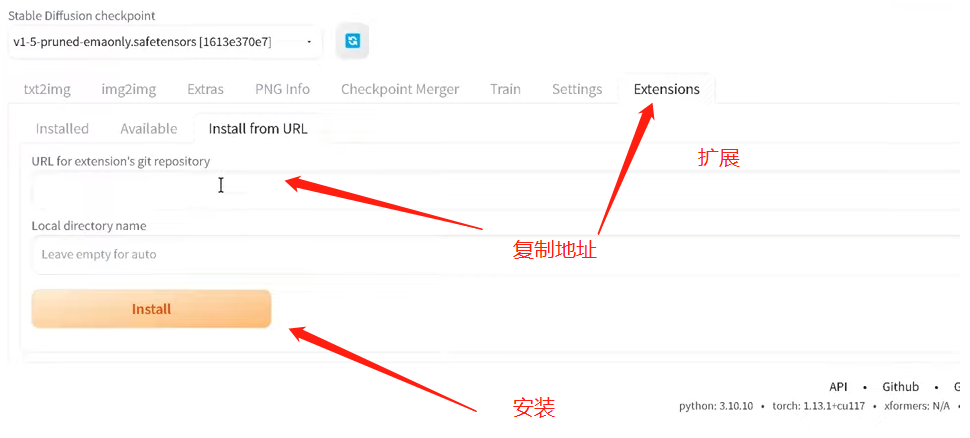
这时候你看到的界面应该还是全英文,为了方便使用,我们的第一件事就是先做汉化、选择最上面的标签中的Extension
URL一栏填汉化插件地址:https://github.com/VinsonLaro/stable-diffusion-webui-chinese.git 点击Install安装,完成后重启即可
于是,我们就进入了stable diffusion的主界面
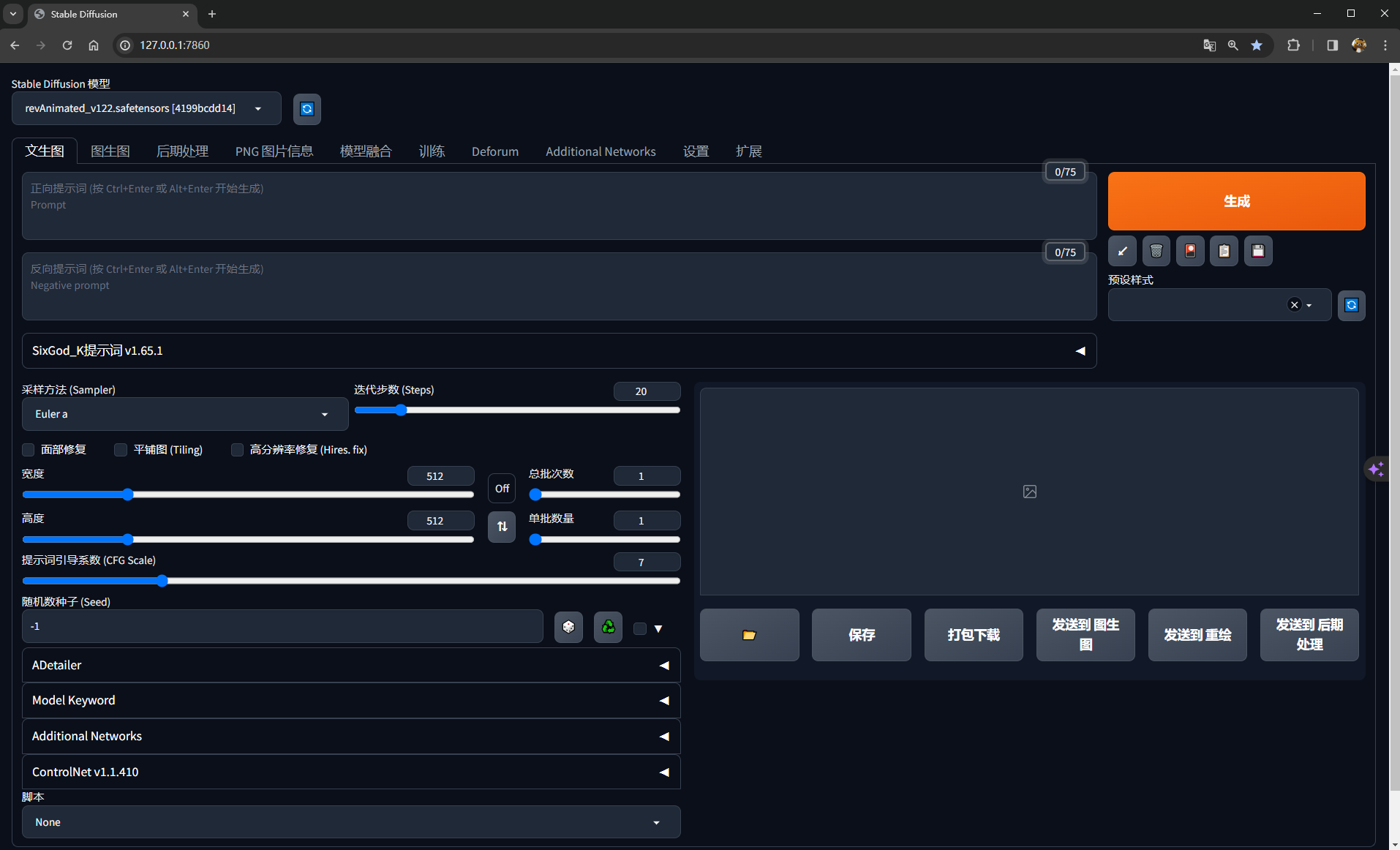
至此,我们的stable diffusion就安装部署好了!
如何使用
要明白如何使用,首先我们需要了解stable diffusion的界面的各个参数都代表什么,如何调整
提示词

提示词又分为正面提示词和负面提示词,正面提示词就是你希望stable diffusion绘图的目标方向,而负面提示词则是你希望stable diffusion避免的方面
例如我们填以下正面提示词
(masterpiece), (best quality), (super delicate), (illustration), (extremely delicate and beautiful), (dynamic angle), white and black highlights, (legendary Dragon Queen:1.3)(1 girl), Hanfu, (complex details) (beautiful and delicate eyes), golden eyes, green pupils, delicate face, upper body, messy floating hair, messy hair, focus, perfect hands, (fantasy wind) <lora:FilmVelvia2:1> <lora:koreaface15:1>
我们填以下负面提示词
nsfw,logo,text,badhandv4,EasyNegative,ng_deepnegative_v1_75t,rev2-badprompt,verybadimagenegative_v1.3,negative_hand-neg,mutated hands and fingers,poorly drawn face,extra limb,missing limb,disconnected limbs,malformed hands,ugly,poorly drawn face,mutated,lowres,nsfw,logo,text,mutated hands and fingers,ugly,deformed

我们会得到以下一个美丽的小姐姐

可以看到,已经十分接近真人照片了,但其实还有一些细节是可以再优化的,可以通过提示词或重绘等功能继续优化
采样方法
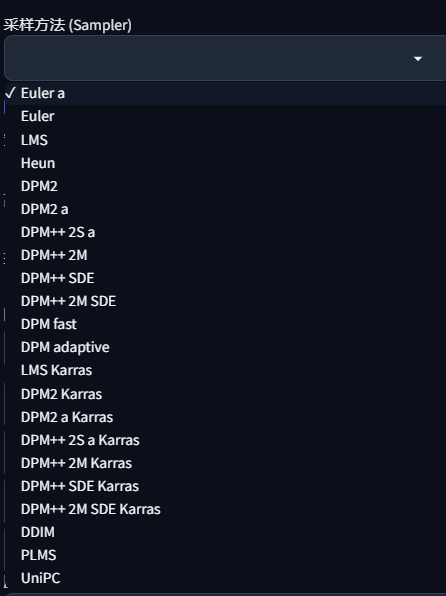
采样方法是不同的采样算法进行绘图,不同的采样方法,最终得出的效果也是不尽相同,以下是主要几个采样方法所适合的模型
- Euler a :适合插画,二次元,漫画风,tag利用率仅次与DPM2和DPM2 a,环境光效不行,构图有时很奇葩
- Euler:柔和,也适合插画,环境细节与渲染好,背景模糊较深。
- Heun:单次出图平均质量比Euler和Euler a高,但速度最慢,高step表现好。
- DDIM:适合宽画,速度偏低,高step表现好,负面tag不够时发挥随意,环境光线与水汽效果好,写实不佳。
- DPM2:该采样方法对tag的利用率最高,几乎占80%+
- DPM2 a:几乎与DPM2相同,对人物可能会有特写
- PLMS:单次出图质量仅次于Heun。
- LMS:质感OA,饱和度与对比度偏低,更倾向于动画的风格
- LMS Karras:会大改成油画的风格,写实不佳。
不同的采样方法对应不同的迭代步数,不同的模型,都有不同的效果,希望你能多试试其中的不同
以上采样方法对比来自:http://www.codeforest.cn/article/3578
另外也可以参考大佬的采样器教学:【stablediffusion采样方法完整教程】 https://www.bilibili.com/video/BV1iW4y1D7RW/?share_source=copy_web&vd_source=b8d0b2c4c1a84965a2546f0efe2f5759
模型
模型分为几种类型
| 模型 | 存放路径 | 描述 |
|---|---|---|
| Checkpoint | stable diffusion安装目录\models\Stable-diffusion | 也叫Ckpt模型或大模型,是绘图的基础主模型,不同的大模型有不同的绘图风格 |
| VAE | stable diffusion安装目录\models\VAE | 搭配主模型使用,起调色和微调作用 |
| Embedding | stable diffusion安装目录\models\embeddings | 提词打包模型,可以生成指定角色的特征、风格或画风 |
| Hypernetwork | stable diffusion安装目录\models\hypernetworks | 类似Embedding模型的效果,常用语画风、效果的转换 |
| LoRA | stable diffusion安装目录\models\Lora | 搭配主模型使用,用于样式修改 |
使用不同的模型,可以得到不同绘图效果
推荐模型下载:https://civitai.com/models
模型路径解析:https://spell.novelai.dev/
其他参数
- 宽度:调整照片宽度
- 高度:调整照片高度
- 面部修复:用于修复面部的怪异,生成人物勾选
- 高分辨率修复:通过算法放大图片的分辨率
- 提示词引导次数:用来控制提示词与出图相关性的一个数值。一般来说,CFG设置为5-15之间是最常规以及最保险的数值。过低的CFG会让出图饱和度偏低,过高的CFG则会出现粗矿的线条或过度锐化的图像,甚至于画面出现严重的崩坏。
- 迭代步数:希望AI的绘图次数(配合不同的采样器,需要使用不同迭代步数,一般在20-30即可,并不是越高越好)
- 随机种子:若生成的图像比较满意,可以保存随机种子,用当前随机种子重新生成图片,产生的变化较小
- 总批次数/单批数量:生成图片数量
插件推荐
stable diffusion除了满足基本的绘图需求,以及各种第三方模型的导入以外,它的强大之处还在于有丰富的第三方插件,即我们在安装部署之后安装汉化插件的界面
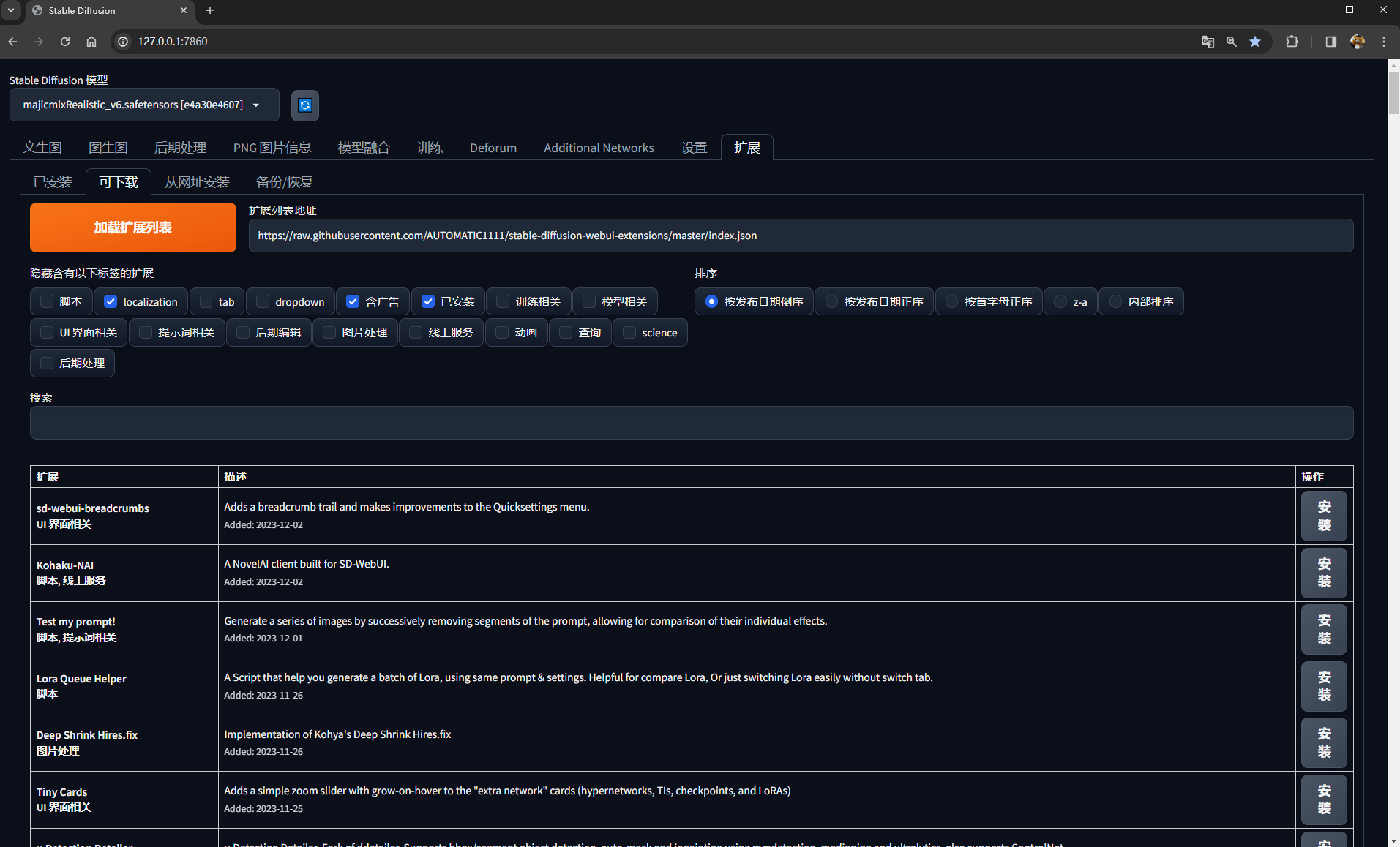
插件安装方式可以是“可下载->加载扩展列表”,然后从列表选择或搜索插件下载,或直接选择“从网站安装”,填写插件的git仓库地址。一般我们从扩展列表搜索即可
提示词插件
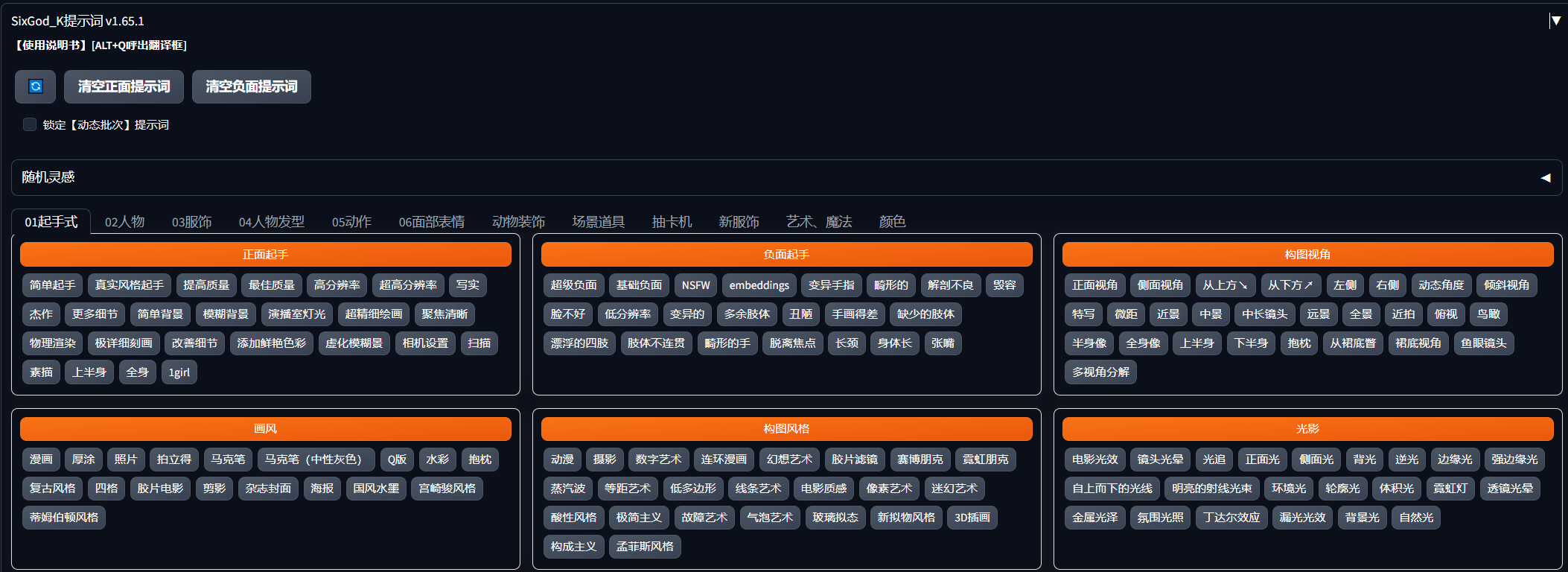
插件名字:sd-webui-prompt-all-in-one
插件仓库地址:https://github.com/Physton/sd-webui-prompt-all-in-one
是不是还在苦恼要怎么去描述想要生成的图片?最原始的方法,就是先描述出你想绘制的图像,再根据自己的英文词汇量,或者翻译软件,得到提示词,再填入stable diffusion,这个插件直接提供了常见的描述词的选择,只需要选择点击即可(刚才那个小姐姐就是用这个生成的)
多重宇宙视频插件
插件名字:deforum-for-automatic1111-webui
插件仓库地址:https://github.com/deforum-art/deforum-for-automatic1111-webui.git
是不是经常在短视频软件看见那种炫酷的多重宇宙的视频,再配上宏达的音乐,让自己感觉像梦里的场景变换一样,苦于这样的视频制作需要付费,所以一直没有尝试?其实stable diffusion有插件就能实现!
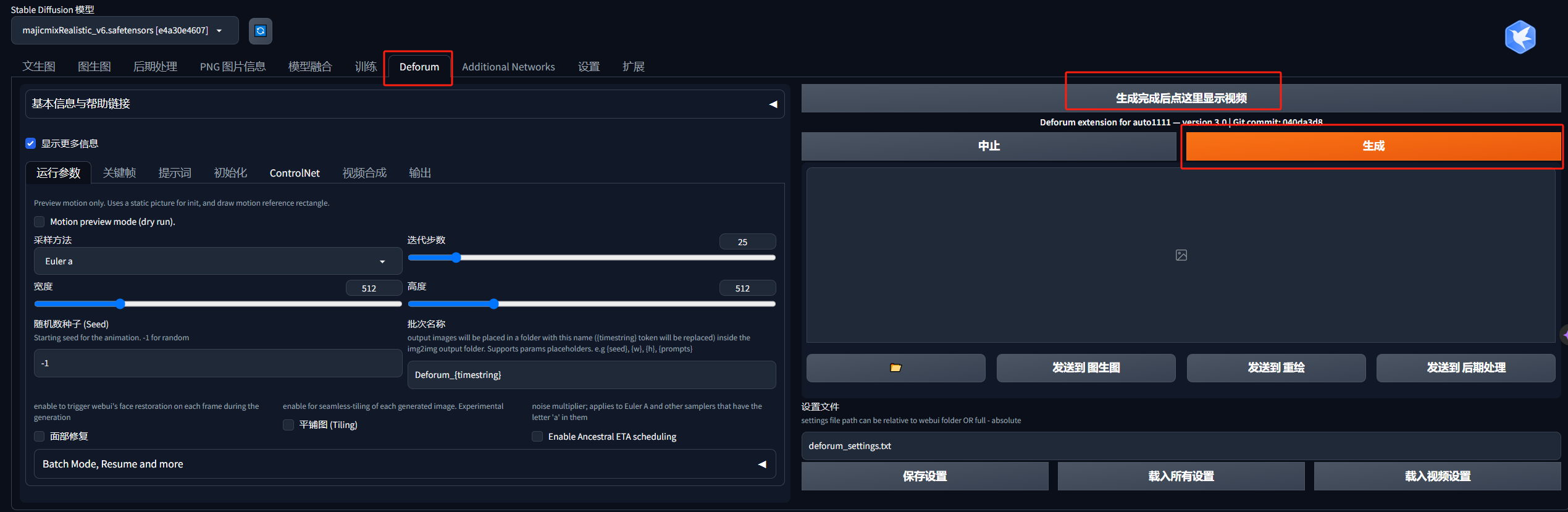
使用方式和正常的文生图差不多,就不多赘述了
这是我拿我的照片作为起始照片生成的钢铁侠


更多插件,就等着你来探索了!
结尾
至此,stable diffusion的大致部署和使用就介绍完了,但这其实还只是冰山一角,文生图,图生图,甚至是Deforum插件,使用方式都大差不差。
stable diffusion有很大的应用前景,比如各种插图、插画、甚至各种美术资源。经过一定使用的训练,它一定能提高你的工作效率!
下面,我们欣赏AI美图吧!




Q.E.D.

