










Java开发中,并发编程属于相当重要的一个知识点,可以说,Java的并发能力,是成就今日Java地位的因素之一。Java的并发编程由浅入深实质上是包含Java(API)层、JVM(虚拟机)层、内核(操作系统)层和CPU层。本文从原理上,由浅入深的解释Java并发原理。掌握并发原理,才能更好地使用Java并发编程!
计算机组成
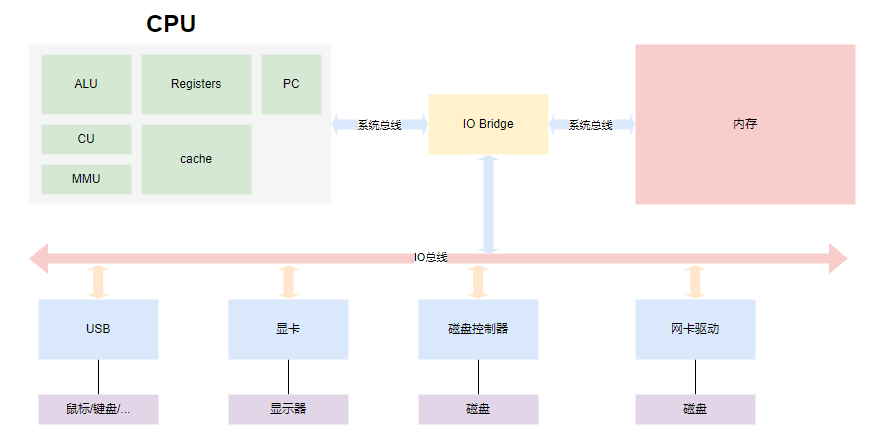
要理解并发编程,我们先从计算机的组成原理说起
ALU(Algorithmatic Logic Unit): 数学逻辑运算单元,执行逻辑计算
Registers:寄存器,用于存数据
PC(Program Control):用于存指令
总线分为:控制线,地址线,数据线
程序读入内存变成01机器码,从内存读取CPU则通过走不同总线确认数据类型是指令还是数据(走哪个地址线由寄存器告知)
程序执行过程:
- 读取可执行文件到内存(机器码)
- 找到程序的起始(main)地址
- 逐步读出指令和数据,并计算回写到内存
进程和线程
进程:一个程序被加载进内存则是一个进程,程序进入内存,分配对应资源(存储,网络等)
线程:共享空间,不共享计算,是可执行的计算单元
进程和线程常见疑问:
- 是否可以使用多进程代替多线程?
理论可行,但实际情况下,不同进程不能共享数据空间,因此需要互相访问,容易让其他进程崩溃- 什么是线程切换?
CPU分时计算,执行A程序到某一行执行后,时间结束,CPU记录指令位置到Cache,然后去执行B程序,同理B的时间结束也会记录B的指令位置到Cache,再切回到程序A的记录为止继续执行- 线程数越多越好吗?
不是,应该根据CPU的核数合理分配线程数,线程数过少会造成CPU利用率不满,不能合理利用多核资源,线程数过多会造成CPU线程上下文切换频繁,反而拖慢整体运行速度- 单核CPU多线程是否有意义?
有意义,多线程能保证多个逻辑能同时运转并合理利用CPU资源,比如程序等待网络输入,但网络没有输入,切换线程能切换到网络接收逻辑接收数据- 一个程序设置多少线程数合适
线程数 = 处理器核数 * CPU期望利用率(0-1) * (1+等待时间/计算时间)
但实际情况中,除了自己的程序,其他程序或操作系统也有自己的线程;且公式中的等待时间和计算时间是无法预估的,所以最终值要根据压测决定
CPU并发控制
缓存一致性
CPU访问速度远大于内存访问速度,为了充分利用CPU的计算能力,在CPU和内存中引入缓存,使二者速度相对匹配
CPU到内存中间有三层缓存l1,l2,l3
CPU读取数据会先到一级缓存l1寻找,找不到则去l2寻找,再找不到则去l3寻找,最后找不到才去内存找,找到数据之后,再往回读的过程中,又会把数据分别缓存到l3,l2,l1中,这样下次访问相同数据只需要访问l1缓存即可
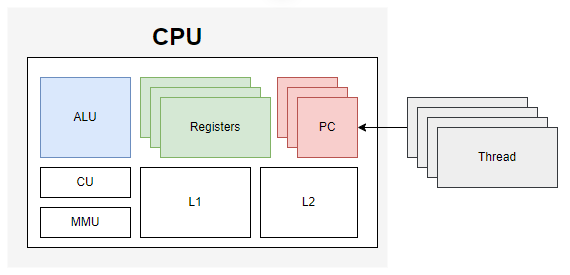
多核CPU架构

超线程架构
即所谓的4核8线程,8核16线程
一个ALU计算单元对应多个寄存器(Registers)和程序计数器(PC),即多个寄存器和程序计数器可以存多个线程的数据,由ALU在CPU内部进行线程切换,这样就省去了线程数据的上下文切换
缓存行
CPU在缓存过程中,缓存的是一个缓存行,即一块的数据(64bytes),这样防止下次访问相邻数据时,还需要走一遍所有缓存的读取流程
为了保证所有CPU的缓存行数据一致,因此有了缓存一致性协议。不同CPU厂商有不同的缓存一致性协议,最常见的是MESI(Intel),即CPU每个缓存行都会标记四种状态
- Modified:修改的
- Exclusive:独占的
- Shared:共享的
- Invalid:无效的
程序的实际应用中也可以根据缓存行的特性,让定义的数据长度不管往前拼或者往后拼,都保证自己独占一行缓存行,则能保证自己只读到一个CPU中,省去缓存一致性的通知机制的触发,从而提高运行速度
CPU的乱序执行(重排序)
CPU在等待耗时的指令执行的时候,会优先执行后面的指令,以保证执行效率,这样就产生了CPU的乱序执行。
重排序会经过以下过程
源代码->编译器优化重排序->指令集并行重排序->内存级系统重排序->最终执行序列
重排序遵循as-if-serial和happens-before原则
- as-if-serial:无论怎么重排序,程序执行结果不能改变,为遵守这个原则,编译器和处理器都不会对任何存在数据依赖关系的操作进行重排序
- happens-before:用于辅助保证程序执行的原子性、可见性有序性问题
并发控制
CPU层并发控制
- 关中断
在执行完一条指令,当开始执行下一条指令之前检测中断信号,通过一种方式让CPU不响应INTR针脚的中断信号,当CPU完成原子操作后,再让CPU响应INTR信号,对应CPU的两条指令STI(set interrupt flag设置中断标志位)和CLI(clear interrupt flag清除中断标志位),Linux内核中操作函数:
#define local_irq_disable() __asm__volatile_("cli"::"memory")// 关中断
#define local_irq_enable() __asm__volatile_("sti"::"memory")// 开中断
-
缓存一致性协议
- 一个处于M(Modified)状态的缓存行,必须时刻监听所有试图读取缓存行对应主存地址的操作,如果检测到,则必须在操作执行前把缓存行中操作的数据写回内存或者将该值转发给需要这个值的CPU,然后修改状态为S(Shared)
- 一个处于S(Shared)状态的缓存行,必须时刻监听使该缓存行无效或独享该内存的请求,如果检测到,则修改状态为I(Invalid)
- 一个处于E(Exclusive)状态的缓存行,必须时刻监听其他试图读取该缓存行对应主存地址的操作,如果检测到,则必须设置状态为S(Shared),并值给需要的CPU缓存行
- 当CPU需要读取数据时,如果缓存行状态是I(Invalid)的,则需要重新发起读取请求,并把自己设置成S(Shared),如果不是I(Invalid),则可以直接读取缓存中的值,但在此之前,必须要等待其他CPU的监听结果,如其他CPU也有该数据且状态是M(Modified),则需要等待把缓存新到内存或者转发后,再次读取
- 当CPU需要写数据时,只有在缓存行是M(Modified)或者E(Exclusive)的时候才能执行,否则需要发出特殊的RFO指令(Read or Ownership),通知其他CPU置缓存无效(I),这种情况下性能开销是相对较大的,在写入完成后,修改其缓存状态位M(Modified)
-
系统屏障
编译级别屏障和指令级别屏障,CPU执行遇到这种指令,前面必须执行完,后面才能执行
- 总线/缓存锁
通过指令LOCK CMPXCHG memory锁总线或缓存
内核层并发控制
- 信号量与P-V原语
- 互斥量
- 自旋锁
- 读写锁
- 中断控制与内核抢占
- seq锁
- rcu锁
JVM层并发控制
- synchronize
- juc
因此从整体来看JVM的锁机制其实是对OS层(Windows/Linux)锁控制的封装,而OS的锁机制也是对底层CPU级别的4种CPU并发控制的封装

线程与线程池
1. 线程启动
- 继承Thread
- 实现Runnable并赋给Thread
- Executors方式
2. 常用方法
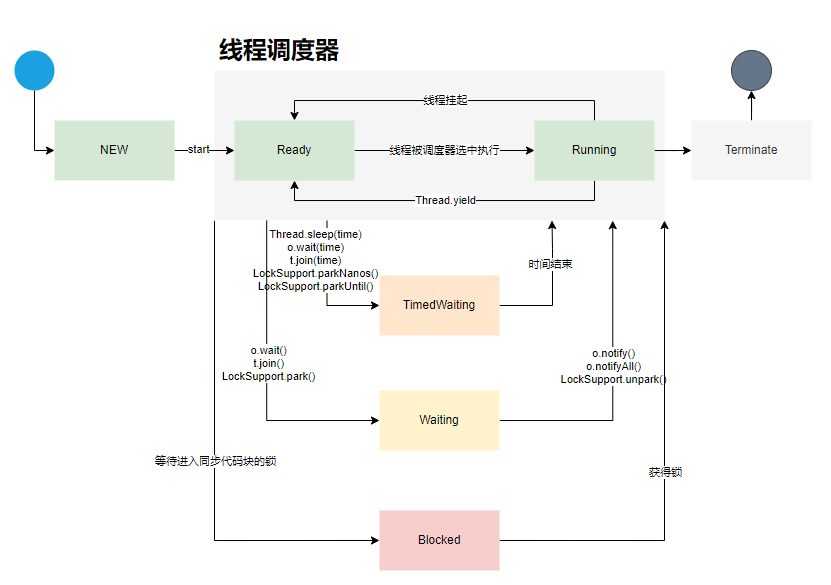
sleep:线程睡眠,CPU调度时不再执行它
yield:让出本次CPU调用,回到等待队列,返回就绪状态
join:切换运行线程,等待join的线程执行完,再继续执行
3. 线程状态
4. 线程池
核心参数
- corePoolSize:核心线程数,除非设置了allowCoreThreadTimeOut,否则核心线程一直存在
- maximumPoolSize:最大线程数,线程池允许创建的最大线程数
- keepAliveTime:当线程数量大于核心线程数时,keepAliveTime用于控制核心线程数外的闲置线程的保持时间
- unit:keepAliveTime参数的时间单位
- workQueue:阻塞队列
- threadFactory:创建新线程的线程工厂类
- handler:线程任务执行失败的处理策略
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
ThreadPoolExecutor核心属性
// 存储了线程池的两个核心属性,int共32位,使用二进制进行存储
// 线程池的工作状态:基于ctl的高三位存储
// 工作线程个数:基于ctl的低29位存储,存储工作线程个数
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// Integer.SIZE = 32
private static final int COUNT_BITS = Integer.SIZE - 3;
// 2的29次方,即工作线程数的最大值
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
其中线程池状态如下:
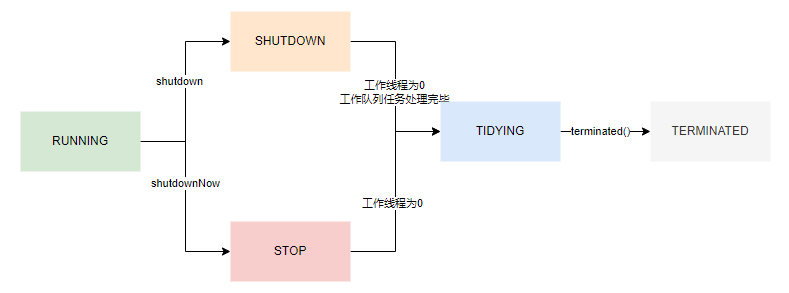
RUNNING:线程池默认状态,正常接收新任务,正常执行任务,正常处理工作队列的任务
SHUTDOWN:不接收新任务,可以正常处理任务,可以正常处理工作队列任务
STOP:不接收新任务,正在执行任务的线程直接强制中断,工作队列的任务不处理,直接作为返回值
TIDYING:过渡状态,调用terminated(),可做钩子回调
TERMINATED:停止状态
execute流程
- 若工作线程小于核心线程数,创建新的核心线程并处理任务
- 若核心线程数已经达到期望值,任务就扔到工作队列
- 若进工作队列失败,则创建非核心线程并处理任务
- 若非核心线程也创建失败,最后回调拒绝策略
整理流程:核心线程 -> 工作队列 -> 非核心线程 -> 拒绝策略
public void execute(Runnable command) {
// 若任务为空,则抛 NPE,不能执行空任务
if (command == null) {
throw new NullPointerException();
}
int c = ctl.get();
// 若工作线程数小于核心线程数,则创建新的线程,并把当前任务 command 作为这个线程的第一个任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) {
return;
}
c = ctl.get();
}
/**
* 至此,有以下两种情况:
* 1.当前工作线程数大于等于核心线程数
* 2.新建线程失败
* 此时会尝试将任务添加到阻塞队列 workQueue
*/
// 若线程池处于 RUNNING 状态,将任务添加到阻塞队列 workQueue 中
if (isRunning(c) && workQueue.offer(command)) {
// 再次检查线程池标记
int recheck = ctl.get();
// 如果线程池已不处于 RUNNING 状态,那么移除已入队的任务,并且执行拒绝策略
if (!isRunning(recheck) && remove(command)) {
// 任务添加到阻塞队列失败,执行拒绝策略
reject(command);
}
// 如果线程池还是 RUNNING 的,并且线程数为 0,那么开启新的线程
else if (workerCountOf(recheck) == 0) {
addWorker(null, false);
}
}
/**
* 至此,有以下两种情况:
* 1.线程池处于非运行状态,线程池不再接受新的线程
* 2.线程处于运行状态,但是阻塞队列已满,无法加入到阻塞队列
* 此时会尝试以最大线程数为限制创建新的工作线程
*/
else if (!addWorker(command, false)) {
// 任务进入线程池失败,执行拒绝策略
reject(command);
}
}
JVM内存屏障
所有jvm规范的虚拟机,必须实现4个屏障
- LoadLoad屏障:对于语句Load1;LoadLoad;Load2,在
Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据读取完毕 - LoadStore屏障:对于语句Load1;LoadStore;Store2,在
Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕 - StoreLoad屏障:对于语句Store1;StoreLoad;Load2,确保
Store1数据的存储对其他处理器可见(刷新到内存中),并在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见 - StoreStore屏障:对于语句Store1;StoreStore;Store2,确保
Store1数据的存储对其他处理器可见(刷新到内存中),并在Store2及后续所有写入操作执行前,保证Store1的写入对所有处理器可见
JVM的4个内存屏障通过JVM调用汇编的LOCK指令实现,而不是CPU层提供的mfence和lfence指令,LOCK即锁住总线
最新openjdk源码的实现中,JVM的内存屏障是通过调用编译器的内存屏障实现的
bytecodeinterperter.cpp
int field_offset = cache -> f2_as_index();
if(cache->is_volatile()){
if(support_IRIW_for_not_multiple_copy_atomic_cpu){
OrderAccess:fence();
}
}
orderaccess_linux_x86.inline.hpp
inline void OrderAccess::fence(){
if(os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#enif
}
}
lock指令用于多处理器中执行指令时对共享内存的独占使用。它能将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应缓存失效。并且它还提供有序指令无法越过这个内存屏障的作用
volatile原理
volatile的作用:
- 可见性:一个线程修改,另一个线程能立马可见
在多核CPU中,当一个核修改了缓存行数据后,会通过MESI机制去通知其他CPU去修改他们本地的缓存行状态:底层首先会让自己的缓存行状态改为Modified,然后通过缓存锁(若数据跨缓存行,则需要锁总线)通知其他CPU对应的缓存行状态失效(Invaild),其他核在读取对应数据时,就需要从主内存中重新获取
若变量修饰了volatile关键字,那么在缓存行数据修改后,会立即写回到主内存,这样就能保证其他核在拿对应数据的时候是拿到最新的数据,即线程可见性
- 禁止重排序:禁止指令重排
volatile在JVM层会对写操作前加StoreStore屏障,在写操作后加StoreLoad屏障,对读操作前添加LoadLoad屏障和后添加LoadStore屏障
StoreStoreBarrier
volatile write
StoreLoadBarrier
LoadLoadBarrier
volatile read
LoadStoreBarrier
cas原理
cas即compareAndSwap,java中的AtomicXXX类底层都是compareAndSwap操作,最终通过JVM层调用的底层lock cmpxchg 指令实现
cmpxchg本身不具有原子性,在cas操作中可能被修改,而前面lock指令则是规定lock之后的指令完成之前,其他CPU不能对其做修改
synchronized原理
对象结构布局
对象在内存中的布局
| 对象头 | markword | 8bytes |
|---|---|---|
| 类型指针 class pointer |
4bytes(jdk默认压缩指针) | |
| 数组长度(数组对象独有) | 4bytes | |
| 对象体 | 实例数据 instance data |
数据大小 |
| 对齐 | 对齐 padding |
对齐到被8整除 |
因此new Object()对象在开启指针压缩的情况占用16字节(本身12字节,最后对齐到16字节),未开启指针压缩的情况也占用16字节(无需对齐直接16字节)
JVM对象对齐
不同于缓存行的64字节的对齐,JVM是以8字节的倍数进行对齐
JVM本身并不决定对象的内存布局,而是根据特定的JVM实现(Hotspot)以及底层硬件架构的要求来进行内存布局。内存布局和填充大小的决策通常取决于多种因素,包括处理器架构、缓存行大小、内存对齐要求以及性能优化的目标。
以下是一些原因解释为什么 JVM 不会自动以64字节进行填充:
- 处理器架构差异:不同的处理器架构具有不同的缓存行大小。虽然在x86和x86-64架构中,常见的缓存行大小是64字节,但并不是所有架构都是如此。一些嵌入式系统或其他处理器可能具有不同的缓存行大小。
- 内存利用率:在内存布局中添加额外的填充字段可能会浪费内存,尤其是在大规模应用中,这可能会导致更多的内存消耗。因此,内存布局通常需要在性能和内存利用率之间进行权衡。
- 复杂性:根据缓存行大小进行自动填充需要更复杂的内存管理和对象布局算法。这可能会增加 JVM 的实现复杂性,并引入潜在的性能开销。
- 应用依赖性:不同的Java应用程序对内存布局的需求可能不同。一些应用程序可能更关注性能,而愿意付出更多内存,而另一些应用程序可能更关注内存节省。自动以64字节填充可能不适用于所有情况。
因此,JVM通常提供了一些灵活性,允许开发人员根据应用程序的需求进行手动优化。如果内存布局需要特定的填充,开发人员可以根据需要进行手动调整。这种灵活性可以根据具体的使用情况进行性能优化和内存管理。
以上回答来自ChatGPT,大致意思应该正确,但具体细节还需辩证观看,我总结主要是以下意思:
- 虽然常见缓存行大小是64字节,但JVM需要兼容所有处理器架构,所以也不能定死了也以64字节对齐。这一点个人感觉不是很重要,尤其对于服务器来说,处理器架构一定是固定的
- 8字节倍数是在性能开销和内存利用率之间找到的一个平衡点,是工程实践的结果,这一点的因素占比更大。
- 如果要求JVM更缓存行大小自动填充需要更复杂的对象对齐算法。同第一点,这一点个人感觉也不是很重要,反过来说,适应不同处理器架构的缓存行应该也不是很费的操作。
- 基本同第二点,不同应用有不同需求,更注重性能还是更注重内存管理,不能一概而论,相比于64字节填充,8字节倍数填充可能更具通用性
以上ChatGPT的回答中,总结下来就一个相对重要的结论:8字节的倍数的对齐算法是JVM在性能开销和内存管理中一个相对平衡的大小
对象的锁信息就记录在markword
锁状态
- 无锁态(new)
| 锁状态 | 25bit | 31bit | 1bit | 4bit | 1bit 偏向锁位 |
2bit 锁标志位 |
|
|---|---|---|---|---|---|---|---|
| 无锁态(new) | unused | hashCode | unused | 分代年龄 | 0 | 0 | 1 |
- 偏向锁
| 锁状态 | 54bit | 2bit | 1bit | 4bit | 1bit 偏向锁位 |
2bit 锁标志位 |
|
|---|---|---|---|---|---|---|---|
| 偏向锁 | 当前线程指针 | Epoch | unused | 分代年龄 | 1 | 0 | 1 |
| 在对象头标记进入的线程指针,下次进入如果还是这个线程,可以直接获操作权限,过程中并未向操作系统申请系统层的锁 |
可通过+UseBiasedLocking开启偏向锁(默认开启), -UseBiasedLocking禁用偏向锁
- 轻量级锁
创建LockRecord对象,记录锁信息,并记录在对象头
| 锁状态 | 62bit | 2bit 锁标志位 |
|||||
|---|---|---|---|---|---|---|---|
| 轻量级锁 | 指向线程中LockRecord对象的指针 | 0 | 1 | ||||
| 撤销对象的偏向锁,在自己的线程生成LockRecord对象,在竞争的对象中记录竞争的LockRecord的指针。然后开始自旋争抢锁 |
- 重量级锁
创建Monitor对象(C++实现),记录锁信息,并记录在对象头,替换LockRecord
| 锁状态 | 62bit | 2bit 锁标志位 |
|||||
|---|---|---|---|---|---|---|---|
| 重量级锁 | 指向互斥量(重量级锁Monitor对象)的指针 | 1 | 0 |
重量级锁升级:向操作系统(内核)申请资源,linux mutex,线程挂起,进入等待队列,等待操作系统调度,然后映射回用户空间
- GC标记
| 状态 | unused | 2bit 锁标志位 |
|||||
|---|---|---|---|---|---|---|---|
| GC标记 | 空 | 1 | 1 |
锁升级过程
无锁态(new) -> 偏向锁 -> 轻量级锁(自旋锁)-> 重量级锁
特殊升级过程
无锁状态的对象头中存储的hashCode,是identity hash code,即未被复写的java.lang.Object.hashCode()或java.lang.System.identityHashCode(Object)的返回值,而并非用户重写的hashCode方法
hashCode仅当计算过,才会存储到对象头中。
这其中有个疑惑,只有无锁状态的对象头才有hashCode的记录位置,那么其他锁状态的hashCode又存在哪里呢?
- 当对象处于无锁状态并发生了hashCode计算后,如果发生同步操作,它会越过偏向锁,直接升级为轻量级锁,即升级过程如下:
无锁态(new)/hashCode -> 轻量级锁(自旋锁)-> 重量级锁
- 当对象处于偏向锁状态并发生了hashCode计算后,如果发生同步操作,它会越过轻量级锁,直接升级为重量级锁,即升级过程如下:
偏向锁/hashCode -> 重量级锁
- 轻量级锁会在LockRecord中记录hashcode
- 重量级锁会在Monitor中记录hashCode
锁降级过程
发生在GC期间, 如果对象已经不被其他任何人引用了,则发生降级
锁消除
public void append(String str1,String str2){
StringBuffer sb = new StringBuffer();
sb.append(str1).append(str2);
}
锁消除是JVM编译器对代码的优化,如以上代码,编译器发现StringBuffer的整个生命周期都在一个方法体里,它的多线程锁就不再有意义,因此编译器编译会消除其中的加锁过程
锁粗化
public String test(String str){
int i=0;
StringBuffer sb = new StringBuffer();
while(i<100){
ab.append(str);
i++;
}
}
锁粗化也是JVM编译器对代码的优化,如以上代码,编译器发现while100次循环会执行100次加锁解锁,此时JVM会优化为while循环外只进行一次加锁解锁操作
底层实现
1. JVM层
sychronized在JVM层是在同步代码前后增加monitorenter和monitorexit指令
JVM源码在jdk\src\hotspot\share\runtime\synchronizer.cpp
monitorenter进入锁
void ObjectSynchronizer::enter(Handle obj, BasicLock* lock, JavaThread* current) {
if (obj->klass()->is_value_based()) {
handle_sync_on_value_based_class(obj, current);
}
current->inc_held_monitor_count();
if (!useHeavyMonitors()) {
if (LockingMode == LM_LIGHTWEIGHT) {
// 轻量级锁(自旋锁)
// Fast-locking does not use the 'lock' argument.
LockStack& lock_stack = current->lock_stack();
if (lock_stack.can_push()) {
markWord mark = obj()->mark_acquire();
if (mark.is_neutral()) {
assert(!lock_stack.contains(obj()), "thread must not already hold the lock");
// Try to swing into 'fast-locked' state.
// 自旋抢锁
markWord locked_mark = mark.set_fast_locked();
markWord old_mark = obj()->cas_set_mark(locked_mark, mark);
if (old_mark == mark) {
// Successfully fast-locked, push object to lock-stack and return.
// 成功抢到锁
lock_stack.push(obj());
return;
}
}
}
// All other paths fall-through to inflate-enter.
} else if (LockingMode == LM_LEGACY) {
// 偏向锁
markWord mark = obj->mark();
if (mark.is_neutral()) {
// Anticipate successful CAS -- the ST of the displaced mark must
// be visible <= the ST performed by the CAS.
lock->set_displaced_header(mark);
// 如果没有人占用,则设置对象头中的偏向锁记录
if (mark == obj()->cas_set_mark(markWord::from_pointer(lock), mark)) {
return;
}
// Fall through to inflate() ...
} else if (mark.has_locker() &&
current->is_lock_owned((address) mark.locker())) {
assert(lock != mark.locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*) obj->mark().value(), "don't relock with same BasicLock");
// 发现偏向锁记录的拿锁的人是自己,则不需要重新上锁,直接返回
lock->set_displaced_header(markWord::from_pointer(nullptr));
return;
}
// The object header will never be displaced to this lock,
// so it does not matter what the value is, except that it
// must be non-zero to avoid looking like a re-entrant lock,
// and must not look locked either.
// 剩下的情况只可能是有人上了偏向锁,但这个人不是自己,那么这里先撤销偏向锁,后续进行锁升级
lock->set_displaced_header(markWord::unused_mark());
}
} else if (VerifyHeavyMonitors) {
guarantee((obj->mark().value() & markWord::lock_mask_in_place) != markWord::locked_value, "must not be lightweight/stack-locked");
}
// An async deflation can race after the inflate() call and before
// enter() can make the ObjectMonitor busy. enter() returns false if
// we have lost the race to async deflation and we simply try again.
while (true) {
// 获取重量级锁
ObjectMonitor* monitor = inflate(current, obj(), inflate_cause_monitor_enter);
if (monitor->enter(current)) {
return;
}
}
}
monitor的实现对应JVM代码在jdk\src\hotspot\share\runtime\objectMonitor.cpp中324行
// monitorenter 324行
bool ObjectMonitor::enter(JavaThread* current)
每一个对象都会和一个监视器monitor关联。监视器被占用时会被锁住,其他线程无法来获取该monitor。
当JVM执行某个线程的某个方法内部的monitorenter时,它会尝试去获取当前对象对应的monitor的所有权。
其过程如下:
- 若monior的进入数为0,线程可以进入monitor,并将monitor的进入数置为1。当前线程成为monitor的owner(所有者)
- 若线程已拥有monitor的所有权,允许它重入monitor,则进入monitor的进入数加1
- 若其他线程已经占有monitor的所有权,那么当前尝试获取monitor的所有权的线程会被阻塞,直到monitor的进入数变为0,才能重新尝试获取monitor的所有权。
monitorexit退出锁
void ObjectSynchronizer::exit(oop object, BasicLock* lock, JavaThread* current) {
current->dec_held_monitor_count();
if (!useHeavyMonitors()) {
markWord mark = object->mark();
if (LockingMode == LM_LIGHTWEIGHT) {
// 轻量级锁(自旋锁)
// Fast-locking does not use the 'lock' argument.
if (mark.is_fast_locked()) {
markWord unlocked_mark = mark.set_unlocked();
markWord old_mark = object->cas_set_mark(unlocked_mark, mark);
if (old_mark != mark) {
// 解锁
// Another thread won the CAS, it must have inflated the monitor.
// It can only have installed an anonymously locked monitor at this point.
// Fetch that monitor, set owner correctly to this thread, and
// exit it (allowing waiting threads to enter).
assert(old_mark.has_monitor(), "must have monitor");
ObjectMonitor* monitor = old_mark.monitor();
assert(monitor->is_owner_anonymous(), "must be anonymous owner");
monitor->set_owner_from_anonymous(current);
monitor->exit(current);
}
LockStack& lock_stack = current->lock_stack();
lock_stack.remove(object);
return;
}
} else if (LockingMode == LM_LEGACY) {
// 偏向锁
markWord dhw = lock->displaced_header();
if (dhw.value() == 0) {
// If the displaced header is null, then this exit matches up with
// a recursive enter. No real work to do here except for diagnostics.
#ifndef PRODUCT
if (mark != markWord::INFLATING()) {
// Only do diagnostics if we are not racing an inflation. Simply
// exiting a recursive enter of a Java Monitor that is being
// inflated is safe; see the has_monitor() comment below.
assert(!mark.is_neutral(), "invariant");
assert(!mark.has_locker() ||
current->is_lock_owned((address)mark.locker()), "invariant");
if (mark.has_monitor()) {
// The BasicLock's displaced_header is marked as a recursive
// enter and we have an inflated Java Monitor (ObjectMonitor).
// This is a special case where the Java Monitor was inflated
// after this thread entered the stack-lock recursively. When a
// Java Monitor is inflated, we cannot safely walk the Java
// Monitor owner's stack and update the BasicLocks because a
// Java Monitor can be asynchronously inflated by a thread that
// does not own the Java Monitor.
ObjectMonitor* m = mark.monitor();
assert(m->object()->mark() == mark, "invariant");
assert(m->is_entered(current), "invariant");
}
}
#endif
return;
}
if (mark == markWord::from_pointer(lock)) {
// If the object is stack-locked by the current thread, try to
// swing the displaced header from the BasicLock back to the mark.
assert(dhw.is_neutral(), "invariant");
if (object->cas_set_mark(dhw, mark) == mark) {
return;
}
}
}
} else if (VerifyHeavyMonitors) {
guarantee((object->mark().value() & markWord::lock_mask_in_place) != markWord::locked_value, "must not be lightweight/stack-locked");
}
// 重量级锁解锁
// We have to take the slow-path of possible inflation and then exit.
// The ObjectMonitor* can't be async deflated until ownership is
// dropped inside exit() and the ObjectMonitor* must be !is_busy().
ObjectMonitor* monitor = inflate(current, object, inflate_cause_vm_internal);
if (LockingMode == LM_LIGHTWEIGHT && monitor->is_owner_anonymous()) {
// It must be owned by us. Pop lock object from lock stack.
LockStack& lock_stack = current->lock_stack();
oop popped = lock_stack.pop();
assert(popped == object, "must be owned by this thread");
monitor->set_owner_from_anonymous(current);
}
monitor->exit(current);
}
monitor的实现对应JVM代码在jdk\src\hotspot\share\runtime\objectMonitor.cpp中1141行
// monitorexit 1141行
void ObjectMonitor::exit(JavaThread* current, bool not_suspended)
monitorexit释放锁。monitorexit插入在方法结束处和异常处,JVM保证每个monitorenter必须有对应的monitorexit。
- 能执行monitorexit指令的线程一定是拥有当前对象的monitor的所有权的线程。
- 执行monitorexit时会将monitor的进入数减1。当monitor的进入数减为0时,当前线程退出monitor,不再拥有monitor的所有权,此时其他被这个monitor阻塞的线程可以尝试去获取这个monitor的所有权
2. OS层
通过JVM源码可以看到,ObjectMonitor的函数调用中会涉及到Atomic::cmpxchg_ptr,Atomic::inc_ptr等内核函数,执行同步代码块,没有竞争到锁的对象会park()被挂起,竞争到锁的线程会unpark()唤醒。
3. CPU层
内核最终调用到CPU层,依然是lock cmpxchg指令
由于重量级锁需要JVM与OS进行挂起和唤醒的操作,因此这个过程涉及到用户态和内核态的切换,因此这种切换会消耗大量的系统资源。所以,synchronized在Java语言中是一个重量级(Heavyweight)的操作。
Lock
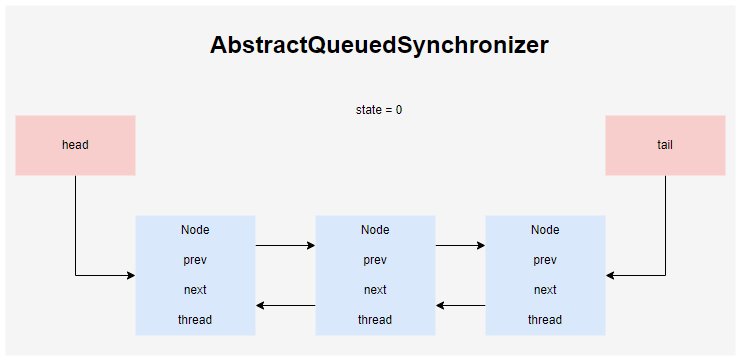
AQS
AQS即AbstractQueueSynchronizer,AQS内部维护一个双向链表
AQS定义了一个实现同步类的框架,实现方法主要有tryAquire和tryRelease,表示独占模式的资源获取和释放,tryAquireShared和tryReleaseShared表示共享模式的资源获取和释放
ReentrantLock
ReentrantLock是基于Lock接口的实现,其内部即通过AQS机制完成的同步操作
lock
lock方法调用AQS进行lock操作
public void lock() {
sync.lock();
}
sync又分为公平锁和非公平锁(可在构造参数指定)
公平锁实现FairSync类:
final void lock() {
acquire(1);
}
非公平锁实现NonfairSync类:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
可以看到公平锁和非公平锁的区别就是,公平锁直接进行acquire方法,而非公平锁会先进行CAS操作,CAS成功之后标记当前线程上锁成功,否则仍然走acquire
tryAcquire
公平锁和非公平锁分两种实现
公平锁:
- state如果为0,如果没有线程排队,CAS拿锁,拿锁成功返回true
- state如果不为0
- 如果当前线程正拿着锁,那么可重复进入,不用重复拿锁
- 否则拿锁失败
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
非公平锁:
- state如果为0,直接进行CAS拿锁,拿锁成功返回true
- state如果不为0
- 如果当前线程正拿着锁,那么可重复进入,不用重复拿锁
- 否则拿锁失败
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
acquire
公平和非公平锁,最终都会调用acquire,当tryAcquire没拿到锁时,会进入AQS排队,调用后面的acquiredQueued以及addWaiter
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
addWaiter
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
acquireQueued
当前线程是否在队伍前面,如果是尝试获取锁资源。若长时间没拿到锁,需要将当前线程挂起
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
// 把当前线程挂起
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
unlock
解锁调用AQS的release方法,无论是公平锁还是非公平锁,最终都会走抽象类AbstractQueuedSynchronier的release方法
public void unlock() {
sync.release(1);
}
release
释放锁的核心是将state从大于0的值更改为0即释放成功
并且release会将AQS中阻塞的线程唤醒,阻塞调用Unsafe的park方法,而唤醒则调用unpark方法
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
Unsafe的park和unpark对应到操作系统的park和unpark,在内核层会将线程从可执行队列移除,不再占用CPU时间片,线程将等待特定条件发生或特定事件发生
Synchronized和ReentrantLock的区别
| synchronied | ReentrantLock | |
|---|---|---|
| 层面 | jvm层实现 | java层逻辑实现 |
| 释放锁 | 同步块代码执行完或发生异常自动释放锁 | 需要手动调用unlock释放锁,一般写到finally方法 |
| 获取锁 | 若其他线程已获取锁,那么当前线程需要阻塞等待 | 可尝试获取锁(tryLock),或指定尝试的超时时间 |
| 锁状态 | 不可判断 | 可判断 |
| 锁类型 | 可重入,不可中断,非公平 | 可重入,可中断,公平非公平 |
ThreadLocal
ThreadLocal绑定在线程本地(Thread)的对象
ThreadLocal底层的Entry使用弱引用,原因是,若使用强引用,即使tl=null,key的引用仍然指向ThreadLocal对象,所以会有内存泄漏。但使用弱引用之后若不及时调用ThreadLocal的remove方法,map中的数据也依然存在,不能被及时回收。因此在使用ThreadLocal时,不用的数据要及时调用remove回收
Disruptor
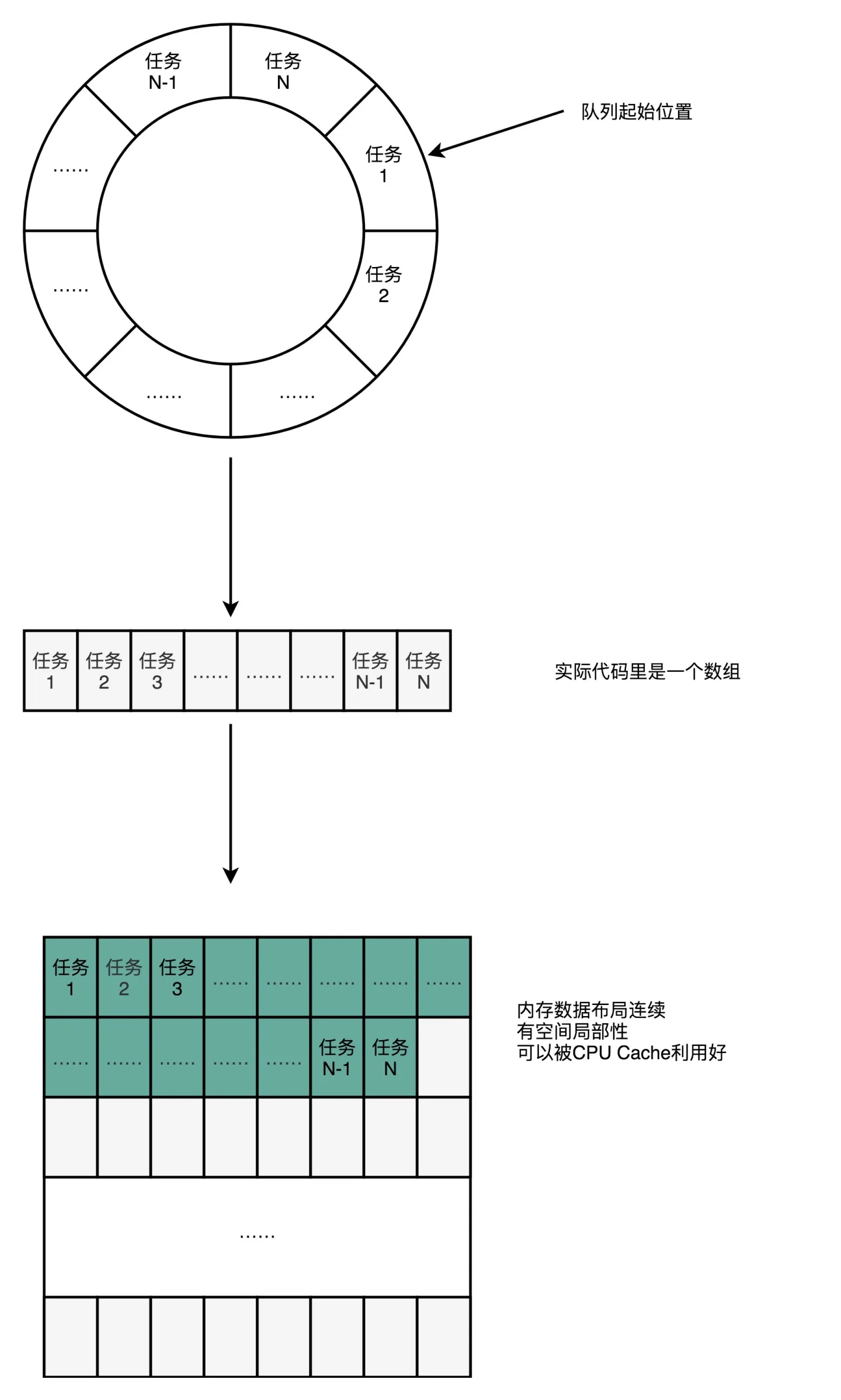
Disruptor是开源的高性能并发框架,是最快的本地消息队列
Disruptor采用环形队列(数组实现)
Disruptor高性能解决方案
无锁设计
Disruptor使用CAS代替锁,使用sun.misc.Unsafe类的CAS相关API
缓存行填充
数组数据基于CPU缓存行的大小进行填充,RingBuffer类中在属性前后各填充7个long类型填充对象(往前56字节,往后56字节),这样不管数据向前拼接还是向后拼接,都能保证数据不会跨缓存行
环形队列
使用有界队列,并且预先创建,避免重复创建对象,降低JVM的GC产生的频率
位运算
底层更多的位数运算来提高查找插入等操作的效率
log4j2底层就是采用disruptor框架
Q.E.D.

